IT・デジタル関連の最新情報や企業事例をいち早くキャッチ
>>さくマガのメールマガジンに登録する

生成AIの技術が急速に進化するなか、RAG(検索拡張生成)は、AIの能力を飛躍的に向上させる重要な技術として注目されています。本記事では、RAGの仕組みやメリットを解説し、活用法を具体的に紹介します。

さくらインターネットが提供している高火力シリーズ「PHY」「VRT」「DOK」を横断的に紹介する資料です。お客様の課題に合わせて最適なサービスを選んでいただけるよう、それぞれのサービスの特色の紹介や、比較表を掲載しています。
RAG(検索拡張生成)とは

RAG(Retrieval Augmented Generation)は、外部情報の検索機能と大規模言語モデル(LLM)によるテキスト生成を組み合わせた自然言語処理(NLP)の技術です。AIが回答を生成する際に外部データベースや情報源から適切な情報を検索して利用することで、より正確で適切な応答を可能にします。
名称の由来は、「情報検索(Retrieval)」と「生成(Generation)」の融合を表現しており、日本語では「検索拡張生成」と呼ばれることが一般的です。RAGは、生成AIの能力をさらに高める手段として注目され、さまざまな業務や研究分野で活用されています。
AI・ディープラーニングに最適な高火力GPUサーバー
>>サービスの詳細を見る
RAGの仕組み
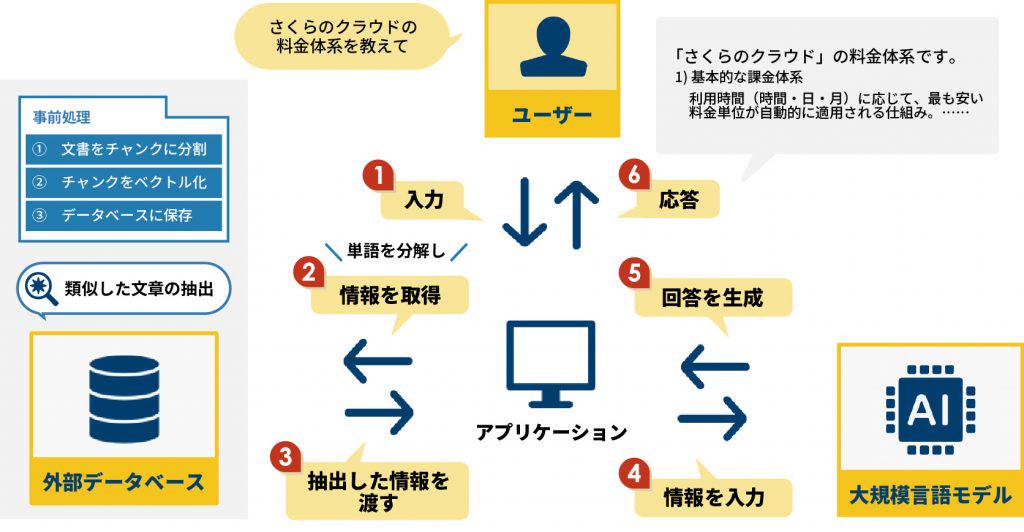
RAGの仕組みは、「検索フェーズ」と「生成フェーズ」の2段階のプロセスで構成されています。ユーザーからの入力をもとに外部情報を検索し、それを活用して最終的な回答を生成します。
| プロセス | 処理の流れ |
| 検索フェーズ | 1 ユーザー入力をベクトル形式に変換 2 外部データベースから関連性の高い情報を取得 3 必要なデータをフィルタリング |
| 生成フェーズ | 1 検索した情報を大規模言語モデルに入力 2 入力情報と文脈に基づき回答を生成 3 結果を整理し、ユーザーに応答 |
RAGの強みは、AIが自ら持つ知識を補完する形で、外部情報をリアルタイムで活用できる点にあります。そのため、最新の情報や専門的な知識を必要とするタスクにおいて、高い有用性を発揮します。
ファインチューニングとの違い
RAGとファインチューニングはAIの精度を向上させるための手法ですが、それぞれ異なるアプローチを採用しています。以下の表に主要な違いをまとめました。
| RAG | ファインチューニング | |
| 基本的な仕組み | 生成AIが回答を生成する際に、外部情報源からの情報検索で補強する | 既存のAIモデルを特定のタスクやデータセットに対して最適化する |
| モデルへの影響 | モデルのパラメータには変更を加えない | モデルのパラメータを調整して新しいタスクに適合させる |
| 実装の難易度 | 比較的実装のハードルが低い | 高度なエンジニアリング知識やスキルが必要なため、実装のハードルは高い |
| データの更新 | 外部データベースの更新で最新情報に対応可能 | 再度学習が必要 |
| 処理速度 | 外部データベースの検索が必要なため、回答までに時間がかかる傾向がある | モデルに組み込まれた知識を使用するため、比較的迅速な回答ができる |
| 用途 | カスタマー対応用のチャットボットなど、最新の情報を必要とする用途に適している | 特定の業界や事業領域に特化したAIの構築に適している |
| コスト効率 | 一般的に高い(再学習が不要) | データの収集・整理、学習のためのAPIコストが必要なため、コスト効率は低い |
それぞれの手法は、得意とするタスクが異なります。RAGはとくに最新情報が必要なシナリオに適しており、ファインチューニングは特定の分野やニーズに特化したAI開発に適しています。
RAGが注目される理由
RAGが注目される理由の一つは、生成AIが抱える課題を効果的に解決できる点にあります。以下に、その具体的な課題を挙げます。
- 情報の古さ:生成AIは事前学習データに基づいて回答を生成しますが、最新情報には対応できません。RAGは外部データベースを活用することで、この課題を解決します。
- クローズド情報へのアクセス:一部の生成AIでは、特定企業や分野における非公開の情報を取り扱うのが困難です。RAGはカスタムデータベースを統合することで、このような情報へ対応できます。
- ハルシネーション:AIが存在しない事実や誤情報を生成する現象(ハルシネーション)を軽減するため、RAGは外部から取得した確実な情報を活用します。
RAGは、これらの課題に対応するために開発され、現在の生成AIの限界を大きく克服する技術として高く評価されています。
RAGの用途例

RAGは、外部情報を効率的に活用することで、さまざまな業務での課題解決を可能にします。以下では、RAGが実務でどのように役立つのか、具体的な活用シーンについて解説します。
チャットボットによる顧客対応力の向上
RAGを活用したチャットボットは、製品情報やFAQを元に迅速かつ的確な顧客対応を実現します。とくに、外部データベースと接続することで、新商品やサービス変更に伴う情報更新もスムーズにおこなえるでしょう。このため、顧客からの質問に正確な回答を提供することで満足度が向上します。
さらに、RAGによる24時間対応の顧客サービスも可能です。たとえば、営業時間外であっても、RAGが関連データを引き出し、適切な回答を自動生成します。これにより、企業は顧客対応の効率化と質の向上を同時に実現できます。
社内問い合わせシステムの作成
社内問い合わせシステムでは、RAGが業務マニュアルや社内規定を活用し、従業員からの質問に自動で対応します。これにより、従業員が情報を迅速に取得でき、業務効率が向上するでしょう。
たとえば、従業員が社内の手続きや制度に関する質問をおこなった際、RAGが関連情報を検索し、回答を提供します。これにより、従来の人力対応による遅延を解消し、重要な業務にリソースを集中できるようになります。
市場調査・マーケティングの効率化
RAGは、市場調査やマーケティング業務においても強力なツールとなります。顧客データや市場動向を分析する際に、外部データベースから必要な情報を取得し、統計的に有用な洞察を提供します。また、トレンド分析やレポート作成の効率化にもつながるでしょう。
たとえば、特定の商品カテゴリの売上動向をリアルタイムで把握し、それを基にしたマーケティング施策を素早く立案できます。このような自動化によって、担当者の業務負担を軽減し、戦略立案に集中できる環境を提供します。
自社フォーマットに沿ったコンテンツ生成
RAGは、営業資料や製品カタログといった自社独自のフォーマットに基づくコンテンツ作成にも適しています。外部データベースから必要な情報を取得し、自動でフォーマットに合わせて整理するため、一貫性のある文書を効率的に生成可能です。
たとえば、新商品の紹介資料を作成する場合、RAGが仕様や特徴を検索し、それを会社の標準フォーマットに組み込みます。これにより、資料の作成時間を大幅に短縮するとともに、情報の正確性と一貫性を確保できます。
コンテナー型GPUクラウドサービス 高火力 DOK(ドック)
>>サービスの詳細を見る
RAGを採用するメリット
RAGを採用することで、以下のメリットを得られます。
- 最新の情報へのアクセスが可能
- より信頼性の高い回答が可能
- 特定の組織に関わる知識への対応が可能
- 追加学習にかかるコストの削減が可能
それぞれのメリットを解説します。
最新の情報へのアクセスが可能
RAGは、外部データベースや社内データベースと連携することで、最新の情報を提供できます。たとえば、製品やサービスに関する情報が更新された場合、即座に反映させることで、正確な回答を提供可能です。
また、リアルタイムな情報提供を実現する仕組みとして、RAGは質問を受け取るたびにデータベースを検索し、現在のデータに基づいて回答を生成します。この動的な処理により、とくに変化の激しい業界や状況において、信頼性の高い情報を迅速に共有できます。
より信頼性の高い回答が可能
RAGは、外部情報源との連携によって回答の精度を大幅に向上させます。たとえば、AIが生成する内容に対して外部データの検証をおこない、事実に基づく回答を保証することで、誤情報のリスクを最小限に抑えられるでしょう。
さらにRAGの仕組みは、生成AI特有の課題であるハルシネーション(虚偽の生成内容)を軽減します。情報源からの直接的なデータ取得を重視する設計により、回答の正確性と一貫性を確保できるのも特徴です。
特定の組織に関わる知識への対応が可能
RAGは、組織特有の情報や専門知識を活用することで、業界や企業に特化した高度な対応が可能です。たとえば、社内の手順書や過去の事例データをもとに、従業員の疑問に即座に回答できます。
組織内に散在する情報を集約し、それを基にした一貫性のある回答を生成することも可能です。
追加学習にかかるコストの削減が可能
ファインチューニングと比較して、RAGはコスト効率に優れています。
ファインチューニングではモデル自体を再学習させる必要がありますが、RAGはデータベースの更新だけで最新情報に対応可能です。この点が、再学習にかかる時間やリソースの削減につながります。
運用面でも、RAGは柔軟性が高いため、特定の変更や拡張に対して迅速に対応できます。
コンテナー型GPUクラウドサービス 高火力 DOK(ドック)
>>サービスの詳細を見る
RAGのデメリット・注意点
RAG導入時には、以下の注意点があります。
- 応答時間が比較的長くなる
- データベースの継続的なメンテナンスが必要
- 機密情報の流出への対策が必要
それぞれの注意点を解説します。
応答時間が比較的長くなる
RAGは、外部データベースを検索して情報を取得するプロセスが含まれるため、応答時間が長くなる場合があります。とくに、大量のデータを扱うシステムや複雑なクエリが必要な場合、検索処理に時間がかかることが課題です。
課題を軽減するには、検索アルゴリズムの最適化やキャッシュの活用が有効です。たとえば、頻繁に利用されるクエリ結果をキャッシュすることで、再検索の負荷を軽減できます。また、データベースのインデックスを適切に設定し、検索速度を向上させることも効果的です。
データベースの継続的なメンテナンスが必要
RAGを効果的に活用するには、データベースの定期的なメンテナンスが欠かせません。情報の更新が遅れると、古いデータが回答に反映され、信頼性を損なう可能性があります。
具体的なメンテナンス方法としては、定期的なデータ更新スケジュールを設定し、新しい情報を迅速に追加することが挙げられます。また、重複や誤ったデータを除去し、データの品質を維持することが重要です。これにより、正確かつ一貫性のある情報提供を実現できます。
機密情報の流出への対策が必要
RAGがアクセスするデータベースには機密情報が含まれる場合があるため、情報漏えいのリスクが懸念されます。たとえば、外部からの不正アクセスや内部からの情報漏えいを防ぐ対策が求められます。
情報漏えい対策をするためには、アクセス制御の実装が不可欠です。具体的には、ユーザー認証や権限管理を厳格に設定し、不正なアクセスを防ぎます。また、データベース通信を暗号化することで、外部からの盗聴を防ぐことが可能です。
さらに、システムの定期的なセキュリティ監査を実施し、潜在的な脆弱性を早期に特定・修正することが推奨されます。
RAGを実装する方法

RAGの実装には、データベースの選定から運用保守まで、複数のステップが必要です。それぞれの段階で適切な手法を選択することが、システムの性能や信頼性を高める鍵となります。以下に、具体的な手順とその注意点を解説します。
| ステップ | 具体的におこなうこと |
| ①データベースの選定 | 利用シナリオに適したデータベースを選び、必要なデータを収集・整理する |
| ②Query Encoderの設定 | 入力クエリを処理するエンコーダを設定し、適切なアルゴリズムとモデルを選択・調整する |
| ③Document Retrieverの構築 | データベースから関連情報を高速かつ精度高く検索する仕組みを実装する |
| ④Answer Generatorの設計 | 検索結果をもとに自然な形で回答を生成する生成モデルを設計し、フィルタリング機能を設定する |
| ⑤システム性能のテストと調整 | システム全体の精度や速度をテストし、運用環境に応じた調整をおこなう |
| ⑥運用保守体制の確立 | データ更新やシステム監視、セキュリティ対応などの体制を整備し、長期的な運用を見据える |
➀ データベースの選定
RAGを構築する最初のステップは、データベースの選定です。データベースはシステムの情報基盤となる重要な要素であり、適切な選択が成功の鍵を握ります。利用目的に応じて、動的な更新が可能なデータベースや静的な情報を保持するデータベースを選択しましょう。たとえば、リアルタイム性が求められる場合には、頻繁に更新可能なデータベースが適しており、一方で固定された情報を活用する場合は、静的なデータベースが最適です。信頼性の高いデータを選定することで、システム全体の品質も向上します。
➁ Query Encoderの設定
次に、Query Encoderの設定をおこないます。これは、ユーザーからの入力をモデルが理解できる形式に変換する役割です。BERTやTransformerといった自然言語処理モデルを用いて、利用する場面に応じてカスタマイズします。Query Encoderの性能が回答の正確性に直結するため、多様なクエリにも対応可能な設計を心がけましょう。また、過学習を防ぎつつ、高い汎用性を持たせることが重要です。
③ Document Retrieverの構築
Document Retrieverは、データベースから関連する情報を効率的に検索する機能を実現します。BM25やベクトル検索など、最適なアルゴリズムを選び、必要に応じて精度と速度を調整しなければなりません。たとえば、膨大なデータベースに対して高精度で関連性のある情報を取得するには、データ構造の工夫や検索条件の最適化が求められます。プロセスの成功は、RAGが正確な情報を迅速に提示できるかどうかに直結します。
④ Answer Generatorの設計
Answer Generatorの設計では、検索された情報をもとに、ユーザーにわかりやすい回答を生成します。生成モデルには、LLM(大規模言語モデル)が広く利用され、回答の自然さや正確性が重視されます。また、誤情報の生成(ハルシネーション)を防ぐために、回答内容のフィルタリングや適切な制御をおこなうことが重要です。ユーザーの利便性を高めるため、回答は簡潔であると同時に具体性を持たせる必要があります。
⑤ システム性能のテストと調整
RAGシステムの構築が一通り完了したあとは、全体の性能をテストし、必要に応じて調整をおこないましょう。性能テストでは、システムの応答速度、検索精度、回答品質を評価します。これにより、実際の利用環境に即した最適化が可能です。テスト結果をもとにシステムを改良し、継続的に評価を繰り返すことで、運用開始後のトラブルを未然に防げます。
⑥ 運用保守体制の確立
最後に、長期的な運用を見据えた保守体制を整えましょう。これは、システムの安定性を保つために欠かせないステップです。データベースの定期的な更新やセキュリティ対策、システム監視などの手順を明確化し、必要な体制を構築します。さらに、障害発生時に迅速に対応できるよう、緊急時の対応フローも事前に用意しましょう。これにより、長期的な運用の効率化とトラブルリスクの低減が期待できます。
コンテナー型GPUクラウドサービス 高火力 DOK(ドック)
>>サービスの詳細を見る
RAGの実装に最適なGPU

RAG(検索拡張生成)の実現には、高性能なGPUの活用が欠かせません。GPUは並列処理能力に優れ、大量のデータを迅速に処理することで、RAGの応答生成や検索プロセスを支えます。また、冷却性能や消費電力も考慮すべき要素であり、運用コストへの影響も検討が必要です。
さくらインターネットが提供するコンテナー型GPUクラウドサービス「高火力 DOK」は、RAGに最適なGPU環境を提供します。NVIDIA H100を搭載し、秒単位課金の柔軟な料金体系を採用。初期費用なしで利用可能で、国産クラウド環境による高い安全性を備えています。
さらに、コンテナー技術を活用しているため、環境構築の手間を省き、スムーズな導入と運用を実現します。これらの特長により、「高火力 DOK」はRAGの効果的な実装を目指す企業や研究者にとって、有益な選択肢となるでしょう。
コンテナー型GPUクラウドサービス 高火力 DOK(ドック)
>>サービスの詳細を見る
まとめ
RAG(検索拡張生成)は、生成AIと外部データベースを統合することで、より信頼性が高く正確な情報生成を可能にする技術です。外部データから最新情報や特定領域の知識を取り込み、精度の高い回答を生成できる点が特徴です。これにより、企業や研究分野での応用が広がり、特定分野に特化した回答や最新情報の提供が可能になります。
一方で、データベースの管理や処理環境の整備が課題となる場合もあり、運用コストやセキュリティへの配慮が欠かせません。RAGは、生成AIの実用性をさらに高める技術として、今後も利用が拡大されていくでしょう。
コンテナー型GPUクラウドサービス 高火力 DOK(ドック)
>>サービスの詳細を見る
さくらインターネットが提供している高火力シリーズ「PHY」「VRT」「DOK」を横断的に紹介する資料です。お客様の課題に合わせて最適なサービスを選んでいただけるよう、それぞれのサービスの特色の紹介や、比較表を掲載しています。

 New
New
 New
New







