IT・デジタル関連の最新情報や企業事例をいち早くキャッチ
>>さくマガのメールマガジンに登録する


さくらインターネットが提供している高火力シリーズ「PHY」「VRT」「DOK」を横断的に紹介する資料です。お客様の課題に合わせて最適なサービスを選んでいただけるよう、それぞれのサービスの特色の紹介や、比較表を掲載しています。
「機械学習を始めたいけど、どんなGPUを選べばいいの?」と悩んでいる方もいるのではないでしょうか?
この記事では、機械学習におけるGPUの重要性や、GPUの選び方、NVIDIA・AMDの比較について、解説します。
機械学習やディープラーニングを始めようとしている方は、参考にしてみてください。
➡︎【キャンペーン実施中】生成AI全力応援キャンペーン~NVIDIA H100 が100時間無料に~
GPUとは
GPU(Graphics Processing Unit)は、もともと映像や画像の処理を高速化するために開発された演算装置です。
現在では、機械学習やディープラーニングなどの分野で、大量のデータを高速に処理する目的でも広く使われています。
とくにニューラルネットワークの学習や推論といった膨大な計算を要する工程では、GPUの並列処理能力が非常に効果的であり、CPUでは実現が難しい高速化やスケーラビリティを実現します。
CPUとの違い
CPUとGPUはどちらも計算処理を担う装置ですが、その設計思想と得意分野には大きな違いがあります。
CPUは少数の高性能なコアで複雑な命令を順番に処理し、OSの制御やソフトウェアの実行などに適しています。
一方、GPUは数千もの小さなコアを使って同じ処理を大量に並列でこなすため、同じ演算を大量のピクセルや行列に対して繰り返す処理が必要となる画像処理や機械学習において、力を発揮するのです。
以下の表に両者の特徴をまとめました。
| 項目 | CPU | GPU |
| 主な用途 | OS制御、一般アプリケーション処理 | グラフィックス処理、機械学習、並列計算 |
| コアの数 | 数個~数十個ほどの高性能コア | 数百~数千個ほどの小規模コア |
| 処理方式 | 逐次処理(直列処理) | 並列処理(大量の同時処理) |
| 得意な処理 | 複雑な制御、判断が必要な処理 | 大量の単純な計算処理(例:行列演算) |
| 機械学習との関係 | 小規模・補助的な用途に向く | 大規模モデルの学習・推論に最適 |
このように、CPUとGPUは補完的な関係にあり、タスクの種類に応じて適切に使い分けることが重要です。とくに機械学習のように、大量のデータを同時に処理する場面では、GPUの性能が大きなアドバンテージとなります。
機械学習とディープラーニングの違いを解説
AI(人工知能)の中核技術である「機械学習」と、その一分野である「ディープラーニング」について、それぞれの基本的な概念と両者の違いを解説します。 これらの技術がGPUとどのように関わっているのかを正しく理解していきましょう。
機械学習とは?
機械学習(Machine Learning)とは、コンピューターが大量のデータからパターンやルールを自動的に学習し、その知識をもとに予測や分類などをおこなう技術です。従来のように人間が細かい手順をすべてプログラミングするのではなく、データを与えることでコンピューターが「経験を積んで賢くなる」仕組みと考えると理解しやすいでしょう。
たとえば、迷惑メールの判定や画像認識のように、明確なルールをつくるのが難しい課題に対して、機械学習は有効です。この技術では、過去の事例と正解ラベルを含むデータと、分析に用いるアルゴリズムをセットで使います。コンピューターはアルゴリズムに従い、データの傾向を学び、判断に役立つモデルを構築するのです。
このプロセスにより、未知のデータに対しても精度の高い予測が可能になります。実際には、ECサイトでの商品レコメンドや、医療画像の解析、工場設備の異常検知など、さまざまなビジネスシーンにおいて導入が進んでいます。
ディープラーニングとは?
ディープラーニング(Deep Learning、深層学習)は、機械学習の一種であり、人間の脳を模倣したニューラルネットワークを多層構造で用いる点に特徴があります。とくに、複雑なパターンを自動的に認識・抽出する能力に優れており、近年のAIブームを支える中核技術のひとつです。
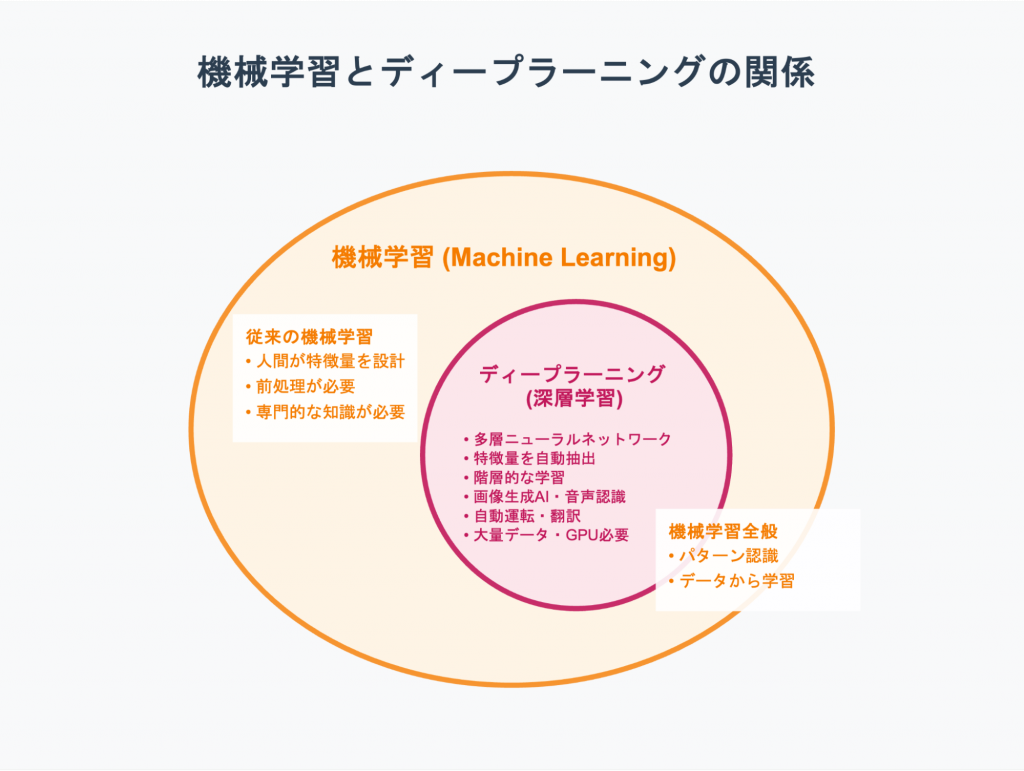
従来の機械学習では、画像や音声などのデータから「何を学習させるか」を人間が判断し、特徴量(特徴的なパターン)をあらかじめ設計する必要がありました。この作業は専門性が高く、場合によっては非常に手間のかかる工程です。
しかし、ディープラーニングでは、コンピューターがデータから特徴量を自動的に学び取るため、前処理の負担が大幅に軽減されます。
ニューラルネットワークの階層が深くなることで、入力に近い層は単純な要素(線・色・輪郭)を捉え、上位層ではそれらを組み合わせて抽象的な概念(顔・物体・意味)へと理解を広げていきます。この階層的な処理能力があるからこそ、画像生成AIや音声認識、自動運転、翻訳などの高度なタスクでも高精度な成果を上げられるのです。
ただし、ディープラーニングは高度な計算処理を必要とし、学習には大量のデータとGPUなどの高性能な計算資源が欠かせません。これにより、処理時間やインフラコストも無視できない要素となります。
機械学習でGPUが重要視される理由
機械学習、とくにディープラーニングにおいて、GPUが重要視される3つの理由を解説します。
- 優れた並列計算能力
- ディープラーニング計算との親和性
- 学習時間の短縮
機械学習でなぜGPUが必要になるのかをチェックしていきましょう。
優れた並列計算能力
GPUが機械学習の現場で重要視される理由は、並列計算能力の高さにあります。CPUは複雑な処理を一つひとつ正確にこなすのが得意ですが、同時に処理できるスレッド数には限界があります。数十個ほどのコアしか持たないCPUでは、大量の同時処理には向いていません。
その点、GPUは数千にも及ぶコアを搭載しており、もともと画像処理やグラフィック描画などの並列作業を効率化する目的で設計されました。この構造が、機械学習、とくにディープラーニングにおける行列演算やベクトル演算のような反復的処理と相性がよいのです。
CPUを「少人数のエキスパート集団」とするならば、GPUは「何千人もの作業員が同時に単純作業をおこなう巨大工場」のような存在と表現できます。結果として、GPUを活用することで、従来は数週間かかっていた学習タスクが数日、あるいは数時間で終わることも珍しくありません。
このように、高速かつ大規模な並列処理を可能にするGPUの構造は、機械学習の進化と実用化を支える土台となっています。大量データを扱うAI開発において、GPUは重要な存在といえるでしょう。
ディープラーニング計算との親和性
機械学習のなかでも計算負荷が高いディープラーニングでは、GPUの存在が一層重要になります。その背景には、ディープラーニングでおこなわれる処理が、GPUのアーキテクチャと極めて高い親和性を持っているという事実があります。
ニューラルネットワークの学習や推論では、大量の行列同士の掛け算や畳み込み演算といった、同じ種類の計算を何度も繰り返す処理が中心です。これらは主に掛け算と足し算による積和演算で構成されており、GPUの得意とする並列処理によって高速化が可能です。
さらに、近年のGPU、とくにNVIDIAの製品に搭載されている「Tensorコア」は、AI用途に特化した演算回路として設計されています。Tensorコアは、FP16やINT8などの低精度演算を活用することで、従来よりも少ないリソースで高い計算効率を実現できます。
学習時間の短縮
GPUが機械学習、とくにディープラーニングの現場で重宝されるもうひとつの大きな理由は、優れた計算性能によって、モデルの学習時間を大幅に短縮できる点です。これにより、単なる時間の節約にとどまらず、研究や開発の全体的なスピードアップにもつながります。
とくに、ディープラーニングではモデル構造や学習条件(ハイパーパラメータ)の最適化を目的に、何度も実験と調整を繰り返すことが欠かせません。もし1回の学習に数週間もかかってしまえば、アイデアを試す回数が限られ、開発効率が大きく低下してしまいます。
GPUを活用すれば、こうした学習時間を数日、数時間にまで短縮することが可能です。結果として、より多くの仮説をすばやく検証し、改良のサイクルを高速で回せます。たとえば、従来1か月かかっていた実験を3日で終えられれば、単純計算でも10倍の試行錯誤が可能になるわけです。
この反復速度の向上は、モデル精度の改善や新たな発見につながるチャンスを広げてくれます。企業や研究機関にとっては、試行回数の多さがそのまま競争力になる場合もあり、GPUは開発効率を押し上げる重要な戦略的リソースといえるでしょう。
機械学習に用いるGPUの選び方
機械学習やディープラーニングの学習・開発を効率的に進めるために、適したGPUを選ぶポイントは、以下のとおりです。
- コスト・価格
- コア数
- メモリ容量・帯域幅
- 冷却性能・冷却方式
- 消費電力
- グラフィックボードの動作環境
コスト・価格
GPUを導入する際、コストは重要な判断基準のひとつです。価格帯は幅広く、数万円のエントリーモデルから、プロフェッショナル向けのハイエンドGPUでは数百万円に達することもあり、予算によって選択肢が大きく変わります。
もちろん、高性能な製品ほど価格も高くなりますが、「高い=最適」とは限りません。重要なのは、どのような用途で使うのかを明確にし、その目的に見合った性能とコストのバランスを見極めることです。無駄なスペックに予算を割かない工夫も求められます。
コア数
GPUの性能を判断するうえで基本となる指標のひとつが「コア数」です。これはGPU内部に存在する演算ユニットの数を指し、NVIDIA製品では「CUDAコア」として表記されることが一般的です。多数のコアを活用して、大量の単純な計算を同時並行で処理できる点がGPUの強みといえます。
とくにディープラーニングのように、行列演算を何度も繰り返す計算処理では、コア数の多さがそのまま学習・推論の速度向上につながるケースが少なくありません。実際、GeForce RTX 50シリーズでも上位モデルになるほどCUDAコア数が増えており、それに比例して処理能力も高まる傾向があります。
ただし、性能はコア数だけで決まるものではありません。アーキテクチャの世代、クロック周波数、Tensorコアの搭載有無やその世代、さらにメモリ帯域など、複数の要素が複雑に絡み合って全体のパフォーマンスが構成されます。
そのため、コア数をあくまで参考指標のひとつとして捉え、用途や予算に応じてほかのスペックやレビューと合わせて比較検討する姿勢が重要です。単純な数字だけに頼らず、全体のバランスを見ることが賢明な選び方といえるでしょう。
メモリ容量・帯域幅
機械学習に適したGPUを選ぶ際、重視すべき要素のひとつがメモリ容量と帯域幅です。GPUメモリ(VRAM)は、学習用のデータや膨大な数のモデルパラメータ、演算途中の一時データなどを高速に処理するための専用領域です。
まず、メモリ容量が不足すると、学習モデルや入力データをメモリ上に展開できなくなり、「Out of Memory」エラーによって処理が中断されてしまいます。とくに、LLM(大規模言語モデル)や高解像度画像を扱うタスクでは、16GB~24GB以上の容量が求められるケースがあり、研究用途では48GBや80GBといった大容量が必要になる場合もあります。
一方、メモリ帯域幅とは、GPUとそのメモリ間でデータをやり取りする速度です。帯域幅が広いほどデータの供給がスムーズに行われ、GPUコアの処理能力を最大限に発揮しやすくなります。GDDR6XやHBMといった高速規格を搭載したGPUは、この点で有利です。
メモリ容量が不足すると致命的な問題に直結するため、想定されるタスクに対して十分な余裕を持たせた選定が重要です。また、帯域幅についてもスペック表や製品レビューを参考にし、性能判断の基準として活用するとよいでしょう。
冷却性能・冷却方式
高性能なGPUは膨大な計算処理をこなすため、消費電力が大きく、それに伴って多くの熱を発生させます。この熱を効率的に処理できない場合、GPUの動作が不安定になり、最悪の場合には故障リスクが高まるおそれがあります。そのため、冷却性能はGPU選定時に見逃せない要素です。
GPUには、一般的にファンやヒートシンクを備えた冷却クーラーが搭載されています。機械学習のように高負荷状態が長時間続く用途では、発熱量も比例して増加します。冷却が不十分だとチップ温度が安全範囲を超え、サーマルスロットリングにより自動的に性能が制限されてしまうこともあるのです。
主な冷却方式は、以下のとおりです。
| 冷却方式 | 特徴 |
| 空冷 | ・ファンで空気を循環させ、ヒートシンクを冷やす方式 ・家庭用PC〜小規模サーバーに多い |
| 水冷 | ・冷却水をポンプで循環させて熱を逃がす方式 ・冷却効率が高く、静音性もよい ・高性能CPU・GPUやオーバークロック用途に向いている |
| 液浸冷却 | ・コンポーネント全体を絶縁性のある冷却液に浸す方式 ・冷却性能が高い ・省スペースで高密度実装が可能 |
GPUのスペックや予算などに合わせて、適切な冷却方式を選びましょう。
同じGPUチップを搭載していても、メーカーやモデルによって冷却機構の構造は大きく異なります。ファンの数やサイズ、ヒートシンクの設計によって冷却効率は変化し、とくに大型クーラーを搭載したモデルは高い冷却能力を持つ傾向があります。ただし、ケースへの収まりや取り回しにも注意が必要です。
また、PCケース内部のエアフローも温度管理に大きく影響します。配線を整理し、吸排気の流れを確保することによって、GPU全体の冷却効果を高めることが可能です。とくに長時間の学習や推論をおこなう環境では、冷却に定評のある信頼性の高いモデルを選ぶことが、安定稼働につながります。
消費電力
GPUはPCパーツのなかでもとくに電力消費が大きいコンポーネントのひとつです。そのため、GPUを選ぶ際には、モデルごとの消費電力を確認し、使用する電源ユニット(PSU)の容量が十分であるかを事前にチェックすることが不可欠です。
とくに機械学習のように長時間GPUを高負荷で稼働させる用途では、電力の消費量が累積し、電気代というランニングコストにも大きく影響を与えます。スペック表には「TDP(熱設計電力)」や「TGP(グラフィックボード全体の消費電力)」といった数値が示されており、これらを目安にするのが一般的です。
たとえば、GeForce RTX 4090はTGPが575Wと高く、PC全体で考えると700W以上の消費が見込まれます。電源ユニットの容量が不足していると、動作が不安定になったり、高負荷時に突然シャットダウンしたりする可能性があります。こうしたトラブルを防ぐためにも、メーカーが提示する推奨電源容量を参考に、余裕を持った電源を選びましょう。
また、電源は単なる容量だけでなく、変換効率や品質も重要な判断材料です。80 PLUS認証などの基準を確認し、高効率なモデルを選ぶことで、電力ロスを抑えられます。GPUの性能と消費電力のバランス、いわゆるワットパフォーマンスにも注目し、総合的に判断しましょう。
グラフィックボードの動作環境(サイズや接続端子など)
高性能なGPUを選んでも、PCに物理的に取り付けられなかったり、正しく接続できなかったりすると、意味がありません。グラフィックボードの選定では、性能だけでなく、サイズや接続規格といった動作環境の適合性を確認することが重要です。
まずチェックすべきはカード本体の物理的サイズです。とくにハイエンドモデルは冷却クーラーが大型化しており、長さ30cm超や厚さ3スロット以上になることもあります。ご使用のPCケースが対応しているか、スペックシートで「対応GPU長」や「拡張スロット数」を事前に確認しましょう。
次に、マザーボードとの接続にはPCI Express(PCIe)スロットが用いられます。通常、異なる世代(PCIe 3.0 / 4.0 / 5.0)の間でも互換性がありますが、GPUの性能を最大限に引き出すには同世代での接続が理想です。加えて、電源ユニットからの補助電源コネクタの種類(6ピン、8ピン、12VHPWRなど)と数量が対応しているかも確認が必要です。
また、映像出力端子にも注意しましょう。使用するモニターがHDMIやDisplayPortなど、どの端子で接続するかによって、対応するGPUモデルが変わることがあります。あらかじめモニターとグラフィックボードの出力規格が一致しているかチェックしておくと安心です。
GPU計算基盤の構築を検討されている方向けに、必要な要素や検討したほうがよいポイントを、以下の資料にてまとめています。無料ダウンロードできますので、参考にしてみてください。
【資料ダウンロード】AI開発のためのGPU計算基盤構築ガイド~インフラ選択の決定版~
機械学習に強いGPUメーカーを比較
機械学習、とくにディープラーニング用途でGPUを選ぶ際に主要な選択肢となるメーカー、NVIDIAとAMDについて、それぞれの特徴や強みを比較解説します。
NVIDIA
2025年5月現在、機械学習、とくにディープラーニング分野において、NVIDIAは高いシェアを誇る事実上の業界標準です。高性能なGPUハードウェアに加え、ソフトウェアと開発支援の面でも他社を大きくリードしています。
最大の特徴は、独自の開発環境「CUDA(Compute Unified Device Architecture)」の存在です。これはNVIDIA製GPUの並列演算機能を最大限に引き出すためのソフトウェアプラットフォームであり、TensorFlowやPyTorchなど主要な機械学習フレームワークの多くがCUDAを前提に設計・最適化されています。
さらに、cuDNN(深層学習向けライブラリ)やTensorRT(推論処理の高速化ライブラリ)など、学習・推論の両面で性能を高めるソフトウェア群も充実しています。公式ドキュメントやチュートリアル、フォーラムでの情報共有が活発で、トラブルシューティング時の参考情報が豊富に見つかるのも開発者にとって大きな利点です。
ハードウェア面では、AI演算に特化したTensorコアを備えたGPUを多数展開しており、個人向けのGeForce RTXや、プロ向けのNVIDIA RTX、データセンター向けのH100/H200シリーズなど、用途と予算に応じて柔軟に選択できます。こうした製品群と支援体制により、NVIDIAは学術・産業の両分野で広く採用され続けています。
AMD
AMDは、ゲーミング向けのRadeon RXシリーズと、HPC・AI用途のInstinct MIシリーズを展開しています。
ソフトウェア面では、AMDはオープンソースのROCm(Radeon Open Compute Platform)を提供しており、主にLinux環境(Ubuntu/RHEL)で利用されます。Windows対応は限定的で、対応GPUやOSの制約がある点に注意が必要です。
機械学習では、PyTorchが公式にROCmをサポートしており、特定構成で安定動作します。TensorFlowは一部バージョンのみ対応、JAXは非対応であり、ほかのライブラリとの互換性も限定的です。
性能面では、特定のワークロードでAMD GPUが優れた電力効率やコスト性能を持つ場合もありますが、AI分野ではCUDAを中心としたNVIDIAの成熟したエコシステムが依然として優勢です。
ROCm環境の構築には、Linuxやドライバ設定の知識が求められ、サポート情報も限られるため、導入前に使用フレームワークとの動作確認が不可欠です。
機械学習に用いるGPUサーバーなら「高火力」シリーズがおすすめ
機械学習に用いるGPUサーバーには、さくらインターネットのGPUクラウド「高火力」シリーズがおすすめです。
用途に応じて選べる3つのプランがあります。
| 高火力DOK(ドック) | 高火力VRT(バート) | 高火力PHY(ファイ) | |
| 概要 | NVIDIAのGPUを使用しDockerイメージの実行ができる、コンテナタスク実行サービス | NVIDIA GPU搭載サーバーを複数のVMに分割し提供。「さくらのクラウド」の サーバーとして利用可能。 単一サービス内でAIアプリケーションを完結できる。 | NVIDIAのGPUを搭載した 物理的なサーバー1台を 丸ごと提供するサービス |
| 搭載GPUモデル | ・NVIDIA V100 x 1 ・NVIDIA H100 Tensor コアGPU x 1 | ・NVIDIA H100 Tensor コアGPU x 1 | ・NVIDIA H100 Tensor コアGPU x 8 ※H200・B200予約受付中 |
| 想定ユーザー例 | 安価かつスポットでNVIDIAのGPUを 利用したいABCIユーザー、AIアプリケーション開発者 | 機械学習のスポット利用や、リアルタイム性の高いAIアプリケーション開発者 | 大企業(メーカーなど)やAIメガベンチャー、研究機関 |
GPUの用途や、必要なスペックに合わせて、適切なプランを選ぶことが可能です。
詳細なスペックや料金については、以下の記事でくわしく解説しているので、チェックしてみてください。
さくらのGPUクラウドサービス|最新GPUで開発・AI学習・研究開発を加速!
まとめ
本記事では機械学習におけるGPUの役割や、CPUとの違い、GPUの選び方を解説しました。GPUの並列処理能力は、計算時間を大幅に短縮し、学習効率を高めます。
GPUを選ぶ際は、予算を基軸に、コア数、メモリ容量、冷却性能、消費電力、PCへの搭載可否を総合的に比較することが大切です。自社の状況に合わせて、適切なGPUを選びましょう。
コンテナー型GPUクラウドサービス 高火力 DOK(ドック)
>>サービスの詳細を見る
さくらインターネットが提供している高火力シリーズ「PHY」「VRT」「DOK」を横断的に紹介する資料です。お客様の課題に合わせて最適なサービスを選んでいただけるよう、それぞれのサービスの特色の紹介や、比較表を掲載しています。

 New
New
 New
New







