
ChatGPT の登場で、AI への期待はさらに膨らんでいます。
しかし、現代の AI にはまだ苦手なことがあります。それは、「複数種類の情報源を参考にした判断」です。
たとえば、画像を解析する AI、音声を解析する AI というのはありますが、両方の情報を統合して状況を判断する AI というのはまだこれからの技術になっています。
そこで研究が進みつつあるのが「マルチモーダルAI」です。
マルチモーダルAI の威力や、活躍が期待される場所について紹介します。
見た目だけでは、真実はわからない
私たちが状況を判断したり、先に起こることを予測したりするときには、「五感」を使います。
たとえば2人の人物が向き合っている「画像」を見せられても、ただ向き合っているだけなのか、おだやかに話をしているのか、あるいは大声で喧嘩をしているのかといったことは、声の大きさという「耳」からの情報がなければわかりません。
また、何か液体が容器に入っているとします。
外見では「何かが入った容器」にしか見えませんが、 私たちはにおいを嗅いで何が入っているか推測することもできます。
しょうゆを薄めた液体なのか、麦茶なのか。においを嗅げば麦茶を選んで飲むことができますが、画像しか判断材料がなければわからない、という状況です。
従来の AI は、単独の種類の情報を処理することには長けています。画像なら画像、音声なら音声、テキストならテキスト、といった具合です。
しかし、単独の種類の情報だけでは、状況を総合的に判断することは難しいといった弱点がありました。
そこで、複数のモダリティ (情報)を統合的に処理する「マルチモーダルAI」が注目されています。
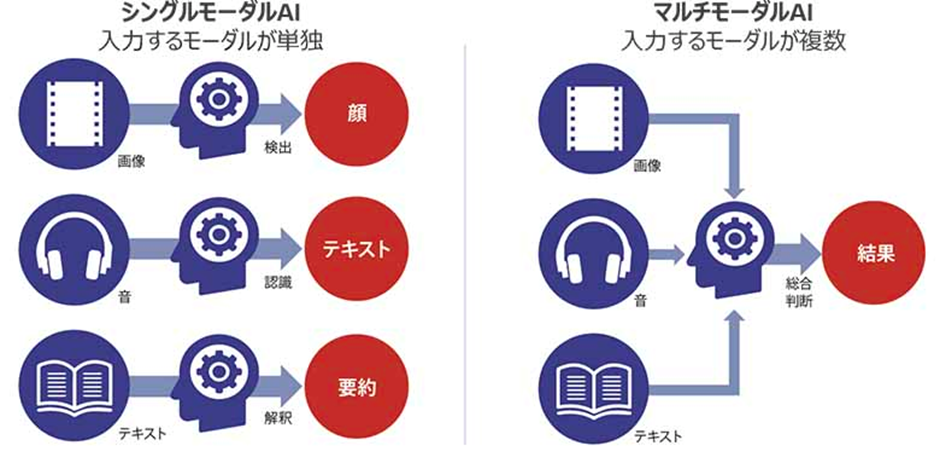
単独の種類の情報についてバラバラにアウトプットするのではなく、複数の種類の情報からひとつの帰結を得る、というのがマルチモーダルAI の特徴です。
マルチモーダルAIの活用法
マルチモーダルAI が活躍しそうな場所はたくさんありますが、期待される身近な例としては防犯カメラがあります。
防犯カメラから得られる画像をもとに、何が起きているかを AI で分析するということは、人間で言えば「視覚のみ」を使って迷惑行為などを検出している状況です。しかしこれだけでは検知しきれないことがあります。
おもに、音を伴うものです。
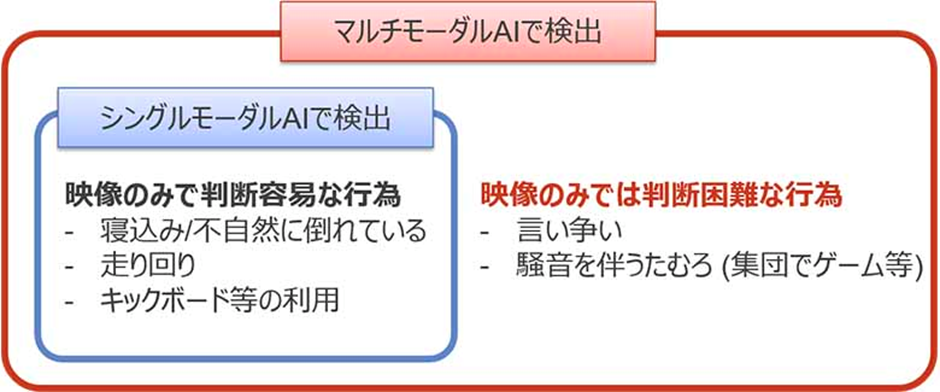
そこで映像だけでなく音声・音量の情報も同時に取り入れ、ものごとを判断できる AI に監視をさせれば、下の図のように映像に映っている人たちがどのような迷惑行為をしているのか正しく判断できるというわけです。

「AI はどんな情報も素早く処理できるもの」と漠然と考えればそれは間違った表現ではありません 。ただ、じつはそれらを横断し「複数の情報を統合する」ということがこれまでなかなかできなかった、というのは意外に思われる人もいらっしゃることでしょう。
アメリカの司法試験にも合格する!?
そしていま世の中を賑わせている ChatGPT ですが、開発者であるアメリカの OpenAI が3月に発表した「GPT-4」はさらに強烈なインパクトを世に与えています。
ChatGPT が文字通り「チャット」一色である一方、GPT-4 は示されたテキストと画像を結びつけて情報を処理できるようになっています。
たとえばユーザーが、質問にこのような画像を添付して GPT-4 に問いかけたとします。

この画像の何が面白いのか? 画像を順に見て答えよ、という質問です。
私たちが見れば、確かにこれは面白いアイテムだと感じます。VGAケーブルでスマートフォンを充電しているように見えるジョークです。
そして、GPT-4 は、この画像について見事な答えを返しているのです。

まずこれらの画像は「ライトニングケーブル」のアダプターであることがわかる、として、それぞれの画像については、
1枚目:VGAコネクター(大きい、青い、15ピンの、一般的にモニターに使用されるもの)が充電口に刺さったスマートフォンの画像である
2枚目:VGAコネクターの画像の上に「ライトニングケーブル」アダプターだと書かれた商品の包装である
3枚目:VGAコネクターの先端にライトニングコネクター(iPhoneやほかの Apple製品の充電に使用するもの)がついているものの拡大
というふうに、画像について説明しています。そして、
「時代遅れの大きな VGAコネクターを、小さくて近代的なスマートフォンの充電口に刺しているというユーモアを示している」
という結論まで披露しています。質問というテキスト情報と画像情報を関連付け、ひとつの帰結に至っているわけです。
説明が苦手な人にとっては、GPT-4 のほうがはるかに説明上手だと感じてしまうかもしれません。「15ピン」という所まで説明がついているのだから立派なものです。
また、GPT-4 はフランスのエリート養成校、エコール・ポリテクニーク(理工科学校)の物理のテストを解いたともしています(※)。
問題文だけでなく、図も参照しなければならないテストです。
さらに、OpenAIは、GPT-4はアメリカの司法試験にも合格できるレベルだとしています(※)。
(※)「GPT-4で『マルチモーダル』の威力痛感、アプリの世代交代に技術者は生き残れるか」日経クロステック
医療分野への応用も期待
また、画像と数値、といったデータの組み合わせは、医療分野での活躍も期待されています。
東京大学などの研究チームは、肝臓の超音波画像と患者情報を統合することで、見つかった腫瘤が良性か悪性かの判別を高精度でできるようになったといいます(※)。
一般的な画像診断AI ではもちろん、画像という1種類のデータに頼ってしまうことになりますが、画像に年齢や性別といった情報、血液データなどの数値も統合させることで、判別がより正確になるのです。
こうした技術が普及すれば、患者にとっては検査の負担が減りますし、医療現場の人手不足の軽減、医療費の削減といったことにもつながります。
もちろん、AI がどれだけ進歩しようと「元になるデータ」を与えるのは人間であり、その点は今後も変わりないものだと筆者は信じています。
ただ、AI の最大の利点はどれだけデータが増えても「疲れる」ことがないというものです。
ミスをしにくいタフなよき相棒として、これからも社会のさまざまなところで AI が活躍してくれる日が来るのを楽しみにしています。

 New
New








