自社構築と外部サービスを比較!GPU基盤導入ガイド
>>資料をダウンロードする
AIアプリケーションの基本概念から5層の技術構造、業界別活用事例まで体系的に解説します。医療・製造・教育・金融・小売での導入効果と開発・運用のポイントを詳しく紹介します。
1. AIアプリケーションとは?基本構造と技術の全体像
AIアプリケーションの定義と技術的な構成要素、研究・開発現場での実践的な視点を解説します。
1-1. AIアプリケーションの定義
AIアプリケーションとは、人工知能技術を活用してデータの解析、予測、自動化をおこなうソフトウェアやシステムの総称です。従来のプログラムが事前に定義されたルールに従って動作するのに対し、AIアプリケーションはデータから学習し、最適な判断や予測をおこないます。
最大の特徴は、明示的なプログラムがなくても、学習データに基づいて合理的な判断をおこなえる点です。この特性により、複雑で変化の激しいビジネス環境で、従来のシステムでは対応が難しかった課題の解決が可能になります。また、継続的に学習することで性能が向上していく点も大きな特長といえるでしょう。
1-2.技術構成とアーキテクチャ
AIアプリケーションは、5つの技術レイヤー(階層構造)と5つの処理段階(データフロー)によって動作します。技術レイヤーは同時に存在する機能層であり、その内部をデータが段階的に流れて処理される仕組みです。
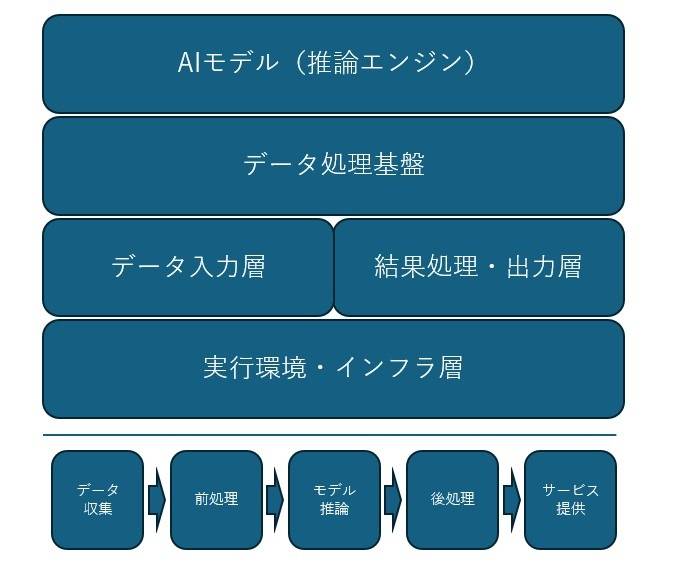
5つの技術レイヤー(階層構造)
データ入力層
センサーデータ、画像、テキスト、音声、ログデータなど、さまざまな形式の生データを収集・受信するレイヤーです。各種データソースから生データを統合し、後続処理のための入力を担います。
データ処理基盤
収集した生データをAIモデルが処理可能な形式に変換する中間レイヤーです。ノイズ除去、正規化、次元削減、データ拡張、特徴量エンジニアリングなどの前処理をおこないます。
AIモデル(推論エンジン)
機械学習モデルによる予測・分類・判断をおこなう中核的なレイヤーです。深層学習モデル、各種アルゴリズム、推論最適化エンジンが稼働し、入力データから有用な洞察を抽出します。
結果処理・出力層
AIモデルの出力を実用的な形式に変換するレイヤーです。結果の解釈、可視化、アラート生成、レポート作成、API出力などを通じて、ユーザーが理解しやすい形式で情報を提示します。
実行環境・インフラ層
全体を支える計算基盤とシステム環境です。GPU/CPU、オンプレミス/クラウド、コンテナ、ストレージ、ネットワークなど、AIアプリケーションの動作に必要なハードウェアおよびソフトウェア資源を構成します。
5つの処理段階(データフロー)
上記のレイヤー構造のなかで、データは次の5段階で順次処理されます。
- データ収集:各種データソースから生データを収集・統合
- 前処理:クリーニング、変換、特徴量抽出の実施
- モデル推論:学習済みモデルによる予測・分類処理
- 後処理:結果の解釈、検証、フォーマット変換
- サービス提供:ユーザーインターフェースやAPIを通じた結果の提示
技術的には、TensorFlow、PyTorch、scikit-learnなどの機械学習フレームワーク上でモデルが動作し、実行環境のDockerコンテナやクラウドサービス上で運用されるのが一般的です。この階層構造により、各レイヤーの独立した開発・運用が可能になり、システム全体の保守性と拡張性が確保されます。
1-3. 研究・開発における技術選定の視点と落とし穴
技術選定では、まず問題設定の明確化がもっとも重要です。分類問題なのか回帰問題なのか、リアルタイム処理が求められるのかによって、適切なアルゴリズムや実行環境が大きく変わります。
ありがちな落とし穴として、最新技術を追い求めすぎる点が挙げられます。データ量が少ない場合や解釈可能性が重視される場面では、従来の機械学習手法のほうが適しているケースも少なくありません。また、計算リソースの見積もりが甘くなりがちで、本番環境でのスケーラビリティを見越した設計が重要になります。技術の新しさよりも、課題に対する適切性を重視して選定しましょう。
2. タイプ別:AIアプリケーションの特徴と設計視点
ここでは、AIアプリケーションの主要なタイプ分類と、それぞれの技術的特徴、設計視点について解説します。
2-1. 代表的な3タイプと用途概要
AIアプリケーションはおもに3つのタイプに分類され、それぞれ異なる技術要素と開発アプローチが求められます。
認識系
画像や動画から特定の物体・パターン・異常を検出・分類するタイプです。製造業では不良品検出、医療では画像診断支援、セキュリティでは顔認証や監視システムなどに利用されます。音声認識による文字起こしや、自然言語処理による文書分類などもこのカテゴリに含まれます。
深層学習の発展により認識精度は大きく向上し、目視検査を上回る精度を達成する事例も増えています。ただし、学習データの質と量が性能に直結するため、データ準備には多大な労力がかかる点に注意が必要です。
予測系
過去のデータから将来の状態を予測したり、大量のデータから有用な知見を抽出したりするタイプです。小売業の需要予測、製造業の設備故障予知、金融業のリスク分析、マーケティング分野の顧客行動予測などに活用されています。
時系列データや統計データをもとに傾向を分析し、意思決定の支援をおこないます。ROI(投資収益率)向上につながる一方で、予測精度の継続的な監視と調整が必要なことが運用上の課題です。
実行系
認識や予測の結果をもとに、実際の行動や制御をおこなうタイプです。自動運転車の走行制御、産業用ロボットの動作制御、スマートファクトリーでの生産プロセス最適化などが代表例です。また、配送ルートの最適化、生産計画、人員配置の最適化などにも応用されています。
複雑な判断や制御を自動化し、作業効率やコスト削減を実現します。とくにリアルタイム性と安全性が求められ、システムの信頼性が最大の技術課題です。
2-2. タイプ別の設計思想と技術的背景
認識系
認識系では、畳み込みニューラルネットワーク(CNN)やトランスフォーマーモデルが中心的な技術です。CNNは画像の特徴量を階層的に抽出し、トランスフォーマーは注意機構という仕組みにより、長い文脈の依存関係を効率的に学習します。
いずれの場合も、学習データの品質と量が性能に大きく影響するため、データ収集とアノテーション(データへのタグ付け)の戦略が重要になります。
予測系
用途に応じてアルゴリズムを使い分けます。時系列予測にはLSTMやGRU、解釈性が重視される場面では決定木やランダムフォレストが用いられます。近年では、トランスフォーマーベースのモデルも時系列予測に応用されており、従来手法との性能比較が重要な設計要素となっています。
実行系
認識・予測結果を実行制御に変換するアルゴリズムの設計がカギとなります。強化学習による最適行動の学習、数理最適化による制約下での最適解探索、エッジコンピューティングによるリアルタイム制御技術などが活用されます。
2-3. 技術選択とアーキテクチャ最適化の考え方
技術選定では、精度要件と処理速度要件のバランスを明確にすることが重要です。リアルタイム処理を求める場合は軽量なモデルが求められ、精度を優先する場合は大規模モデルと十分な計算リソースが必要です。この判断を誤ると、開発後期での大幅な設計変更を強いられる可能性があります。
アーキテクチャ設計では、マイクロサービス構成が推奨されます。モデル推論部分を独立したサービスとして切り出すことで、拡張や更新の柔軟性が向上します。MLOpsという開発手法を導入することで、モデルの学習からデプロイ、監視までを自動化し、継続的な改善サイクルを構築できます。また、障害時の影響を局所化できるため、全体システムの可用性向上にもつながります。
3. 業界別活用事例で学ぶAIアプリケーションの実践と課題
ここでは、実際の導入事例から見えてくる、AIアプリケーションの具体的な効果と技術的課題について解説します。
3-1. 業界別の代表的な事例
AIアプリケーションはさまざまな業界で実用化が進み、それぞれ特有の課題解決に貢献しています。以下に主要な業界での導入事例と、その具体的な効果を紹介します。
医療分野
医師の診断負荷や見落としリスクへの対応として、画像診断支援システムが実用化されています。胸部X線写真から肺がんを検出するシステムでは、従来の目視診断に比べて検出精度の向上と診断時間の短縮が実現しています。眼底写真から糖尿病性網膜症の進行度を自動判定するシステムでは、専門医レベルの精度を保ちながらスクリーニング検査の効率化を図っています。
製造業
品質検査の人的コストや精度のばらつき、設備故障による生産停止といった課題に対して、品質管理AIが活躍しています。不良品検出システムでは、目視検査に比べて検出精度が向上し、検査時間も大幅に短縮しています。また、予知保全システムでは、センサーデータの分析によって故障を事前に予測し、計画的なメンテナンスにより稼働率の向上と保守コストの削減に貢献しています。
教育分野
個別指導の限界や学習進度の把握が難しいという課題に対し、パーソナライズ学習システムが学習履歴や理解度データを分析し、個々の学習者に最適なコンテンツと学習工程を提案しています。適応学習システムでは、回答パターンから弱点を特定し、重点的な学習支援によって学習効率の向上が図られています。
金融業界
不正取引の検出遅れや与信判断の属人性に対し、不正取引検出システムでは機械学習により異常な取引パターンを検出し、不正検出率の向上と誤検出の削減を両立しています。与信審査システムでは、さまざまなデータソースから信用リスクを評価し、審査時間の大幅短縮と貸倒率の低減を実現しています。
小売業界
需要予測の不正確さや在庫リスクに対して、需要予測システムが販売履歴、天候、イベント情報などを統合的に分析し、商品別・店舗別の需要を高精度で予測しています。これにより、廃棄ロス削減や売上機会損失の抑制に貢献しています。また、動的価格設定システムでは、需要と競合状況をリアルタイムで分析し、利益最大化を図る価格を自動で設定することが可能です。
3-2. 実装・運用時に直面する技術的ハードル
AIアプリケーションの実装において最大の課題は、データ品質の確保です。ノイズ除去、欠損値処理、正規化などの前処理が重要であり、学習データに含まれるバイアスはモデルの判断結果に影響をおよぼす可能性があります。とくに、本番環境のデータ分布が学習時と異なる場合、予期せぬ性能低下が発生します。
また、モデルの解釈可能性も重要な論点です。医療や金融などの規制分野では、AIの判断根拠の説明が求められるため、XAI(説明可能なAI)技術の活用が不可欠です。
さらに、運用フェーズではデータドリフト(入力データ分布の変化)に対応するため、継続的な監視体制の構築と、再学習を含む迅速な対応プロセスの整備が必要です。
3-3. 研究・産業応用で未解決の課題と今後の展望
現時点でのAI技術には、少量データでの学習や未知の状況への一般化に課題があります。転移学習やメタ学習による改善が進んでいますが、実用レベルでの課題解決にはさらなる研究が必要です。
また、自動運転や産業ロボットなどのリアルタイム処理分野では、モデルの軽量化と推論速度の向上が不可欠であり、精度と速度のトレードオフ解消が求められます。
今後は、マルチモーダルAI、強化学習の産業応用、量子機械学習、脳型コンピュータによる超低消費電力AIなどの技術進化により、AIアプリケーションの可能性はさらに広がると考えられます。
4. AIアプリケーションを開発・運用する前に知っておくべきこと
AIアプリケーションの開発・運用に取り組む前に、事前に知っておきたい視点や注意点について解説します。
4-1. 開発から導入までの基本フロー
AIアプリケーションの開発は、以下の流れで進行します。各段階での適切な判断が、プロジェクト全体の成否を左右します。
課題設定・要件定義
解決したい課題を明確にし、KPI(重要業績評価指標)を設定します。「何を自動化したいのか」「どの程度の精度が必要か」「リアルタイム性は必要か」などを具体化することが重要です。
データ収集・整備
必要なデータの種類や量を特定し、品質を確保します。既存データの活用可否を検討し、不足分は新たに収集する計画を立てます。
プロトタイプ開発
小規模なデータセットを使って複数のアルゴリズムを試し、最適なモデルを選定します。PoC(概念実証)を通じて技術的実現性を検証し、早期に課題を洗い出すことで本格開発のリスクを軽減します。
本格開発・テスト・デプロイメント
PoCを踏まえて、大規模データでの学習や精度向上を図ります。ユーザー受入テストを経て段階的にリリースし、本番環境での安定動作を確認します。
運用・監視
システムの性能を継続的に監視し、モデルの劣化を検知して再学習などの対策を講じます。こうした運用体制の整備が、長期的な活用のカギとなります。
4-2. 実行環境の選定とリソース運用(オンプレミス/クラウド)
オンプレミス環境はデータ制御とカスタマイズ性に優れますが、初期投資が大きく専門知識も求められます。一方、クラウド環境は初期コストを抑えて最新GPUを利用でき、スケーリングも容易ですが、データ転送コストやセキュリティ面での注意が必要です。
選定時は、データ機密性、処理規模、コスト、運用体制を総合的に評価する必要があります。多くの企業では、開発・検証はクラウド、本番運用は要件に応じてオンプレミスを併用するハイブリッド構成を採用しています。近年では、ベンダーロックインを回避するマルチクラウド戦略も広がっています。
4-3. 持続的な開発体制を支える技術戦略とインフラ最適化
AIプロジェクトの成功には、データサイエンティスト、機械学習エンジニア、インフラ担当、ドメインエキスパートの連携が不可欠です。
技術面では、AIモデルの学習過程や性能を記録・比較できるMLflowやWeights & Biasesによる実験管理、Gitによるコード管理が重要です。インフラ面では、DockerとKubernetesの連携により、開発から本番まで統一された実行環境を維持し、GPUリソースの効率利用と自動スケーリングを実現します。
また、モデルの継続的インテグレーション/デプロイメント(CI/CD)パイプラインを整備することで、品質確保と更新自動化の両立が可能になります。
まとめ
AIアプリケーションは、AI技術を活用してデータから学習し、予測や判断をおこなうシステムです。認識、予測、実行の3つの主要タイプがあり、さまざまな分野で実用化が進んでいます。
導入・開発には、技術面の理解に加えて、適切なチーム体制、実行環境の選定、継続的な監視と改善の仕組みが不可欠です。技術だけでなく、ビジネス課題との整合性を見極める視点も重要です。
AIアプリケーションの開発・運用には高性能な計算リソースが不可欠です。さくらインターネットのGPUクラウドサービス「高火力」シリーズでは、最新GPUを搭載したクラウドサービスとして、プロトタイプ開発から本格運用まで一貫してサポートし、AI技術を活用したビジネス変革を支援します。AI活用の計算リソースに課題をお持ちの方はぜひご相談ください。

 New
New
 New
New







