
多くの企業が DX に取り組むいま、データ活用は重要な要素の1つとなっています。しかし、実際には思うような結果が出ないといった悩みを抱える方も多いのではないでしょうか。
本記事では、滋賀大学 データサイエンス学部教授で、データサイエンス・AIイノベーション研究推進センター 副センター長の河本 薫氏が提唱する「データドリブン思考」をご紹介します。大阪ガスのデータ分析組織の所長を務めた経験から、データをビジネスに活かせない理由や、データ活用を成功させる方法について語りました。
Sansan株式会社が2023年6月に開催した「Sansan Evolution Week 2023」の講演内容をもとにお届けします。
- 「わかる」と「役立つ」の違い
- 「わかる」から「役立つ」に至るために
- データドリブンな意思決定プロセスとは
- 6つに類型化される意思決定プロセス
- ビジネスの課題設定
- データドリブン経営の実現
- データドリブン思考のために必要な3つの能力
- データドリブン経営を目指して
「わかる」と「役立つ」の違い
滋賀大学に赴任した当初、ビジネスと縁が切れるかもしれないという寂しさを感じていましたが、いまもさまざまな企業の方が、滋賀大学のある彦根まで来てくださいます。なぜかというと、悩みごとのご相談のためです。
たとえば、「データサイエンティストを育てたのに、なかなか活躍してくれない」「データ基盤や分析ツールに投資したけれど、投資に見合った成果がでてこない」といったものです。
このような悩みごとを抱えている企業には、共通の違和感を覚えます。それは、「わかる」と「役立つ」の違いを意識できていないのではないか、ということなんです。
機械学習で予測モデルを作る。統計解析をして仮説を検証する。それは、あくまでも「わかる」ということで、「役立つ」にはたどりついていないんですね。
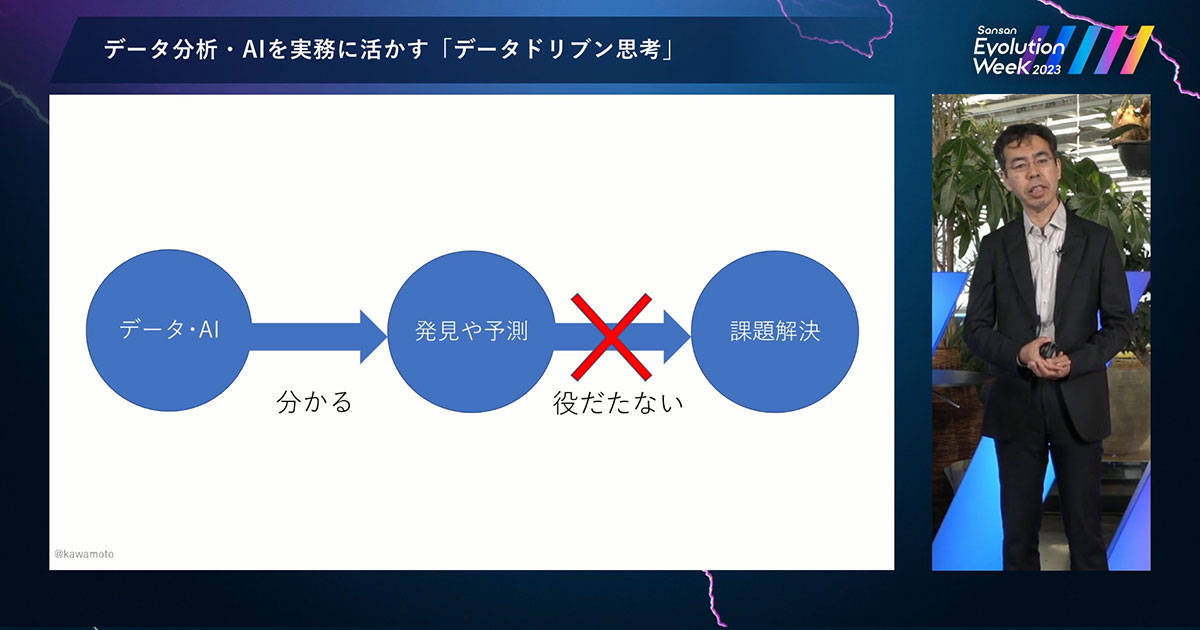
データや AI で発見・予測を得る。これが「わかる」です。しかし、得られた発見・予測が、ビジネスの課題解決につながらない。これが「役立たない」ということです。
極端にいえば、世界一精度の高い予測モデルを作っても、世界ではじめての発見をしても、それが課題解決につながらなければビジネス的には無価値だということです。
「わかる」から「役立つ」に至るために
では、なぜ多くの人たちは、データや AI を駆使しても「わかる」止まりで「役立つ」に至らないのでしょうか。「わかる」止まりの方々は、発見・予測ができれば課題解決ができると勘違いしているからではないかと私は思います。
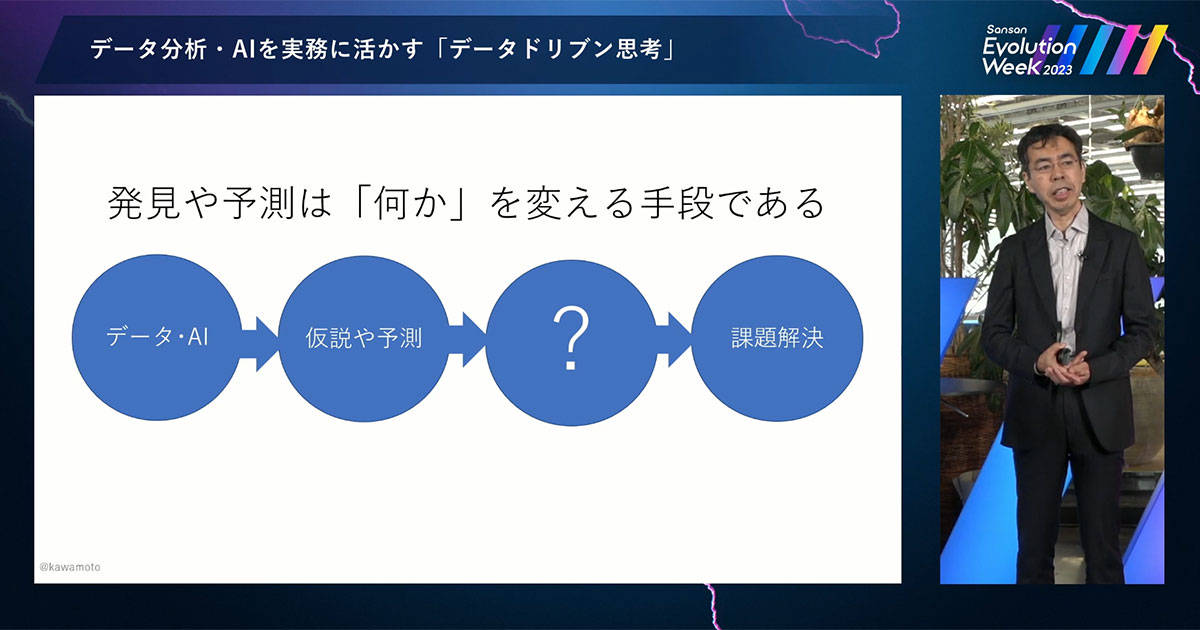
発見・予測は、直接的には課題を解決しません。発見・予測を用いて「何か」を改めることで、課題を解決するわけです。その「何か」を意識できていないのが、「役立つ」に至らない理由だと私は思います。ではこの「何か」というのは、いったい何でしょうか。
この「何か」を考えるヒントが、ダニエル・カーネマンさん(ノーベル経済学賞を受賞した行動経済学の大家)の言葉にあります。「組織とは、意思決定を生産する工場である」。
この「組織」を「企業」と読みかえると、「企業とは、意思決定を生産する工場である」ということになります。
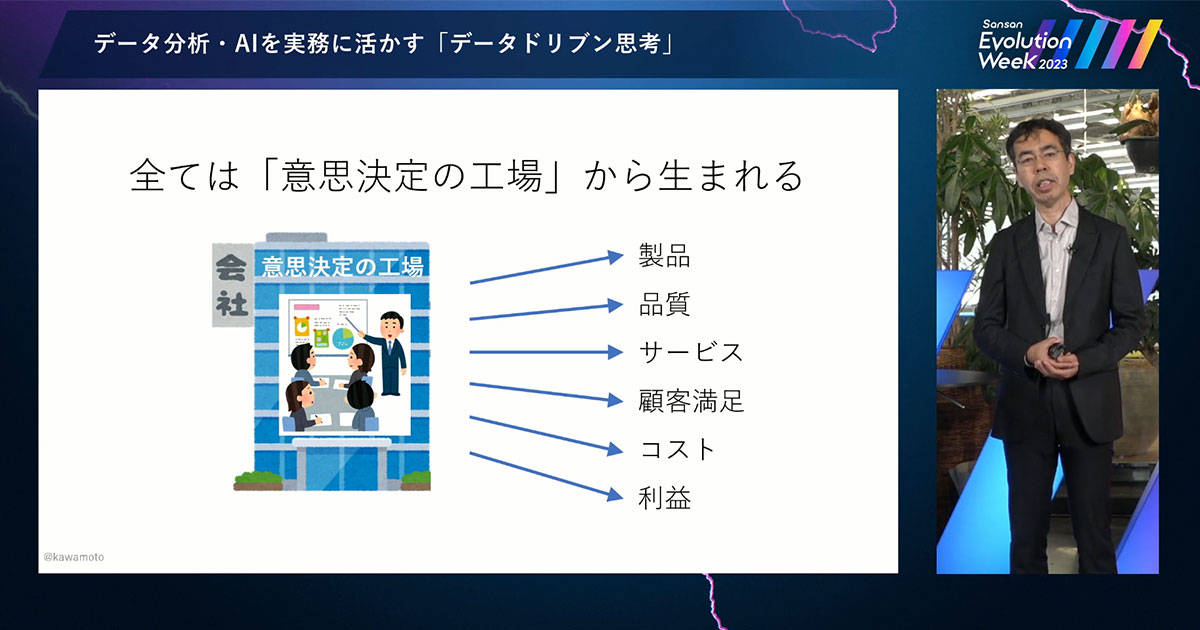
みなさんがお勤めの会社でも、日々いろいろな組織・チームで、そこにいるいろいろな方々が、さまざまな意思決定を生産していますね。その結果として、新製品やサービスが生まれ、品質や顧客満足度、コストや利益が決まっています。
逆に考えると、「最近品質が悪い」「お客さまからクレームが多い」「コストがかさんでいる」「利益が減ってきている」など、さまざまなビジネスの問題が発生するのは、みなさんの会社で作った意思決定、判断や選択がまずいからです。
でも、カーネマンさんの言葉をとらえると、意思決定が悪いのではなく、そういったまずい意思決定を生産するような”生産方法”が悪いということになるんですね。
まずい意思決定を生じさせる「勘と経験を主体とした意思決定の生産方法」を、データや AI を駆使して改善する。それによって、いい判断・決定を作る。その結果、ビジネスの問題を解消できるのです。
さきほどの「何か」とは、つまり「意思決定プロセス」です。
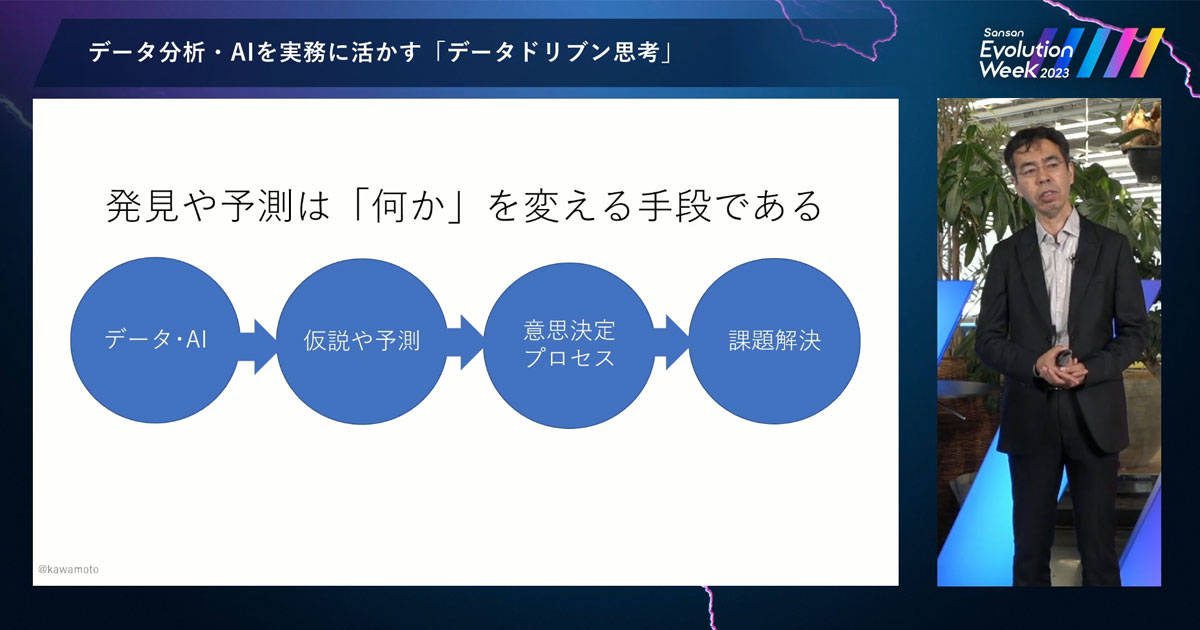
データや AI から得られる発見・予測、これを意思決定の生産方法、すなわち意思決定プロセスを改めることに用います。それによって、従来の勘と経験による意思決定プロセスよりも改善され、これまで生じていた課題を解決する。これが、データと AI で課題解決するプロセスなのだと、私は思っております。
「データや AI から得られる発見や予測を活かした合理的な意思決定プロセス」のことを「データドリブン意思決定プロセス」と私は呼んでいます。

データドリブンな意思決定プロセスとは
どうすれば「データドリブン意思決定プロセス」を作れるのか。
まずやるべきことは、データや AI を活かす意思決定プロセスをきちんと「設計する」ことです。現状の意思決定は、多かれ少なかれ勘と経験で決められています。勘と経験で意思決定している担当者に、どうやって決めたんですかと聞くと、多くの場合は明確な回答が返ってきません。すなわち、意思決定プロセスが暗黙知になっているのです(下図・左)。
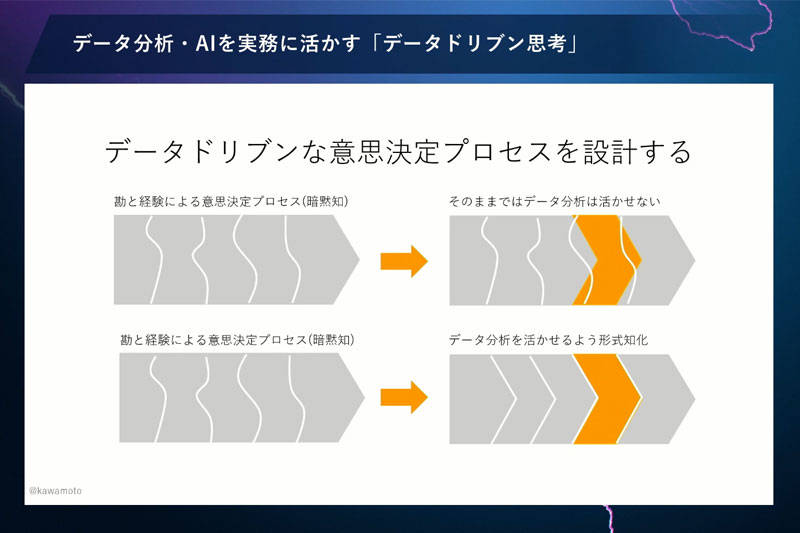
この状態で、なんとなくデータ分析をしても、意思決定プロセスに当てはめることができません。冒頭で述べた、「わかる」けど「役立たない」というのは、こういう状態だと思うんですね。
そのようにならないよう、データ分析をする前に意思決定プロセスを形式知化します(上図・右下)。
具体的には、意思決定プロセスの各ステップをモジュール化する。そして、どのモジュールにデータ分析がどのようにはまるか、データ分析から得られた発見や予測がどのようにそのモジュールに役立つかまで設計する。これを、私は「データドリブンな意思決定プロセスの設計」と考えています。
これから、3つの事例を挙げます。なぜこの意思決定のプロセスを意識しないと「役立つ」に至らないのか、「データドリブンな意思決定プロセスを設計する」とは具体的にどういうことなのか、説明していきたいと思います。
事例1:予防保全活動
1つ目は、予防保全活動の事例です。予防保全活動とは、たとえば空調機器などの機械が故障する前に、故障しそうだなという前兆をとらえて、事前に修理することで突発故障を防ぐことです。
予防保全活動はさまざまな製造業で実施されています。ある工場でも製造機械に対しての予防保全活動がおこなわれていましたが、工場の担当者の勘と経験では、なかなか故障の予兆がわからない。それで、データサイエンティストへ、いまあるさまざまなデータから、故障しそうな予兆をつかんでほしいという依頼をしたわけです。
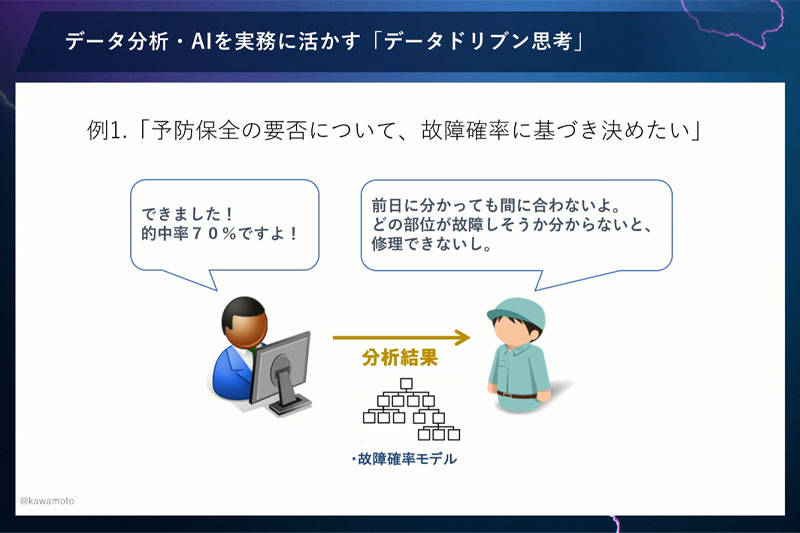
データサイエンティストはがんばって分析をして、できましたと報告にいきます。そうすると、現場担当者に、「前日にわかっても部品の調達が間に合わない」「どこの部位が故障しそうかわからないと修理できない」とか散々に言われてしまう。なぜこんなことが起こるのでしょうか。
これまでの勘と経験で予防保全していたときの意思決定プロセスは、このようなものです(下図)。
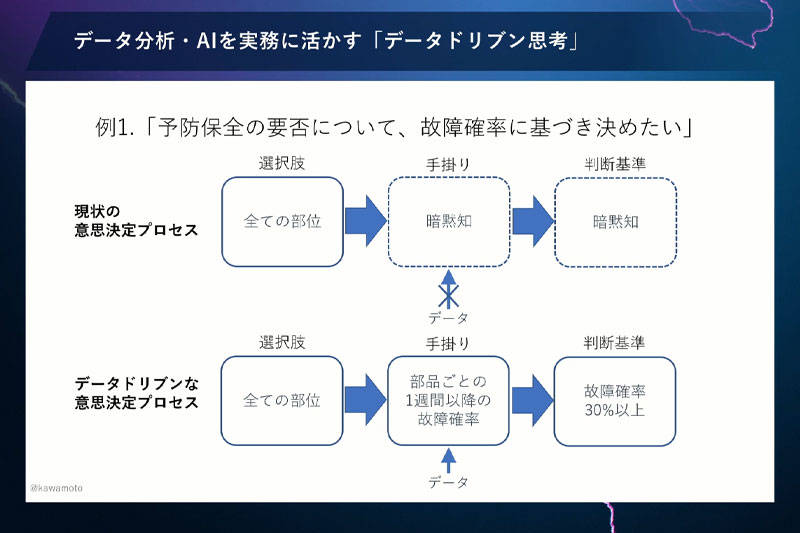
選択肢は、機械を構成するすべての部位です。何を予兆と考え、予防保全をするかという手がかりや判断基準は、これまでは現場担当者の勘と経験、暗黙知だったのです。
この状態のままでは、何をデータ分析すれば結果につながるかがわかりませんよね。そうではなく、データ分析をする前に「手がかりとして何がわかればいいか」を考える。それをもとに「どんな判断基準で予防保全するか」という基準を立て、形式知化しなければなりません。そうすれば、データ分析が無駄に終わって役立たないということにはならないわけですね。
これがデータドリブンな意思決定プロセスを設計するということです。
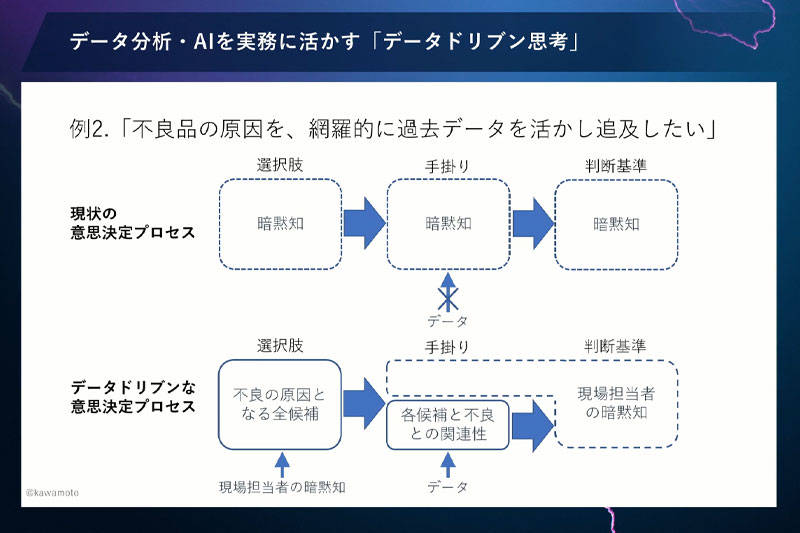
事例2:不良品の原因追及
2つ目は、不良品の原因を追求したいという製造業の事例です。じつはいま、製造業でデータに期待が寄せられているのは、不良品の原因追及です。
製造ラインがどんどん複雑化し、勘と経験だけでは原因追及が難しい。そういったなかで、データは計測できている。そこで、工場担当者は社内のデータサイエンティストに、「すべてのデータを送るから原因追及してほしい」と相談するわけです。

しかし、データサイエンティストが分析してみたところ、「原因がわからない」。じつはこのシチュエーションは日本中の製造業で起こっているのではないかと思っているんです。
なぜこうなるかというと、従来の工場担当者の勘と経験による原因追及は、手がかりや判断基準どころか、不良の原因の候補すら暗黙知なのです。その状況でデータ活用をするのは無茶な話です。こちらの図をご覧ください(下図)。
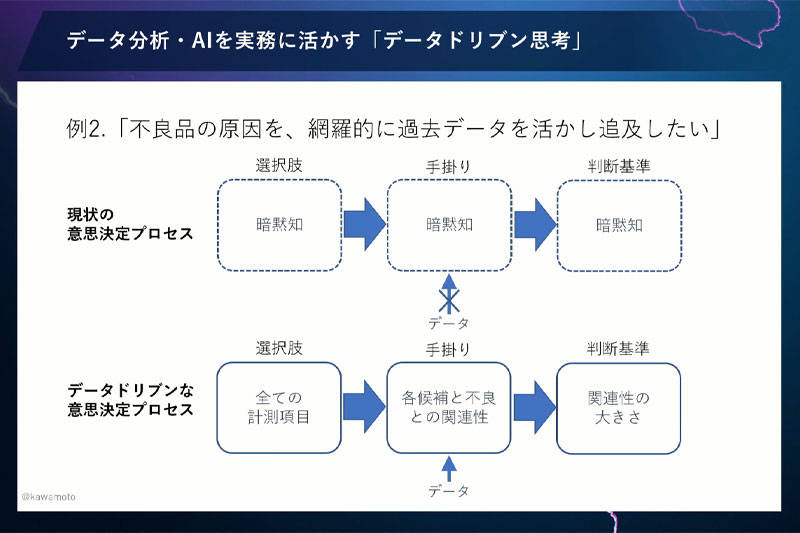
選択肢はすべての計測項目です。手がかりとして、不良の原因となる各計測項目と、不良が発生したかどうかの関連についてデータを用いて分析します。関連が大きいところに原因があると考えられるので、「データ分析よろしく」という構想だったと思うんですね。
でも、じつはこのプロセスには大きな間違いが2つあります。
まず1つ目は、手がかりと判断基準の部分です。データからわかるのはあくまで関連性までで、因果関係はわからないです。データからわかる関連性と、現場担当者が暗黙知として持っている因果関係についてのさまざまな知識、この2つが融合してはじめて、「これが原因だ」とわかるわけです。
さらに、大きな間違いがあります。「すべての計測項目からスタートする」点です。よく「すべてのデータをください」と言うデータサイエンティストの方がいますが、それは、このなかに原因がなかったら私の責任ではないと言っているのと同然なのです。
まずやるべきは、現場担当者の暗黙知を引き出して、不良の原因となる全候補をリストアップすることです。そのなかで、もし計測できていないデータがあるなら、それを計測することからスタートする。これが正しいプロセスだと思います。
事例3:マーケティング(販売施策)
非常にざっくりした話で恐縮ですが、販売施策を考えるとき、担当者の勘と経験や、声の大きい人の意見が通るということがあります。それはよくないということで、データを活かして販売施策を考えるという事例です。
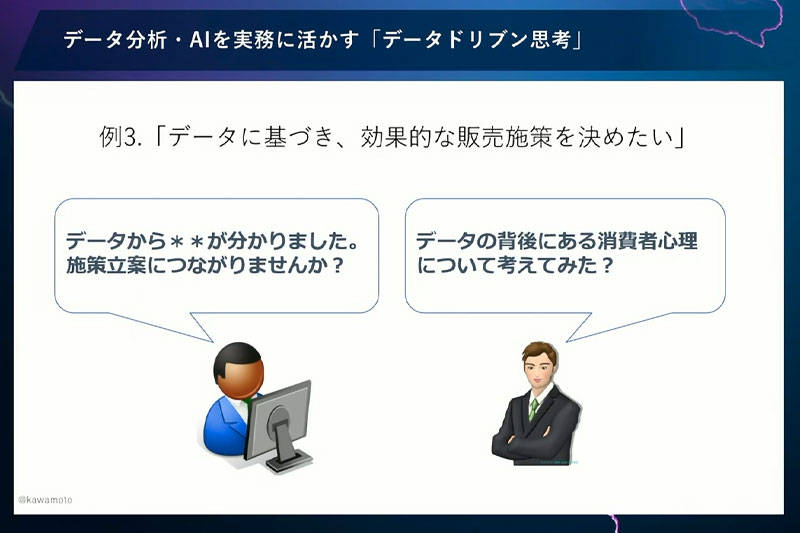
社内のマーケターがデータサイエンティストに分析を依頼したところ、「こんなことがわかりました」と報告がありました。それに対して、マーケターが「データの背後にある消費者心理について考えてみた?」ときくと、データサイエンティストからすると何やらわからなくて会話がかみ合わない。これもよくあることかなと思います。
極端な書き方ですが、勘と経験、声の大きな人の意見で施策を考えていたときは、意思決定プロセス全体が暗黙知だったと考えられます。それに対して、マーケターとデータサイエンティストが考えたプロセスは、このようなものだったと思います(下図)。
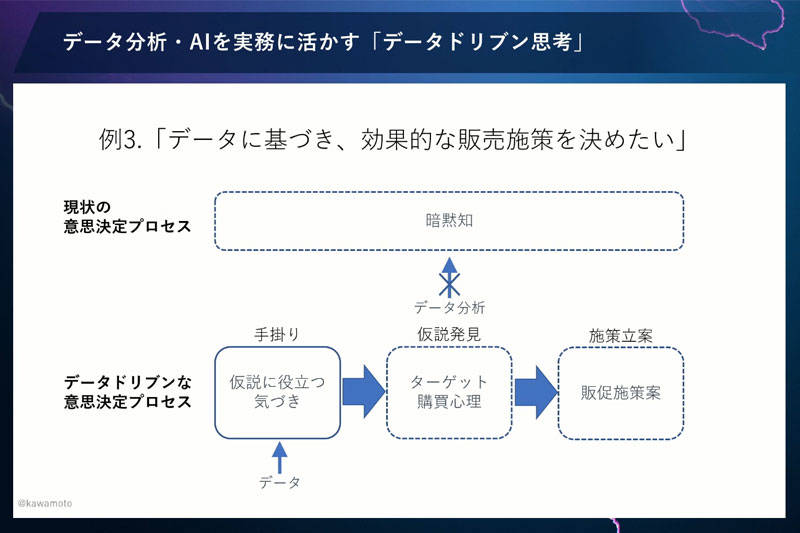
「仮説に役立つ気づきをデータから得られるだろう」「その気づきをもとにターゲットや購買心理について仮説を考えよう」「仮説をもとに販売施策を考えよう」。そのため、まずデータサイエンティストがやることは、データから気づきを見つけることです。
でも、これは2つの点で間違えているんです。まず1つ目は、「手がかり」の部分です。「データから気づきを得て、そこから仮説を考える」という流れはたしかにありますが、「購買心理についての仮説を立て、その確認のためにデータを見る」という逆の流れもあります。「データを見ること」と「仮説を考えること」が行ったり来たりする。両方が一体となって進んでいくというプロセスになるはずですね。
もう1つの大きな間違いは、効果検証が必要な点です。不良品の原因追及の事例とは違い、マーケティングの販売施策は、人の心に対してやっていくものです。施策をやってみて、予想通りの効果を得られるかは、やってみないとわからないですよね。
そのため、データを使って効果検証、A/Bテストなどをする必要があります。もし思ったような結果がでなければ、それはなぜかをデータを使って要因分析する。要因分析をした結果を用いて、また施策を考え直す。このような流れになるかと思います。
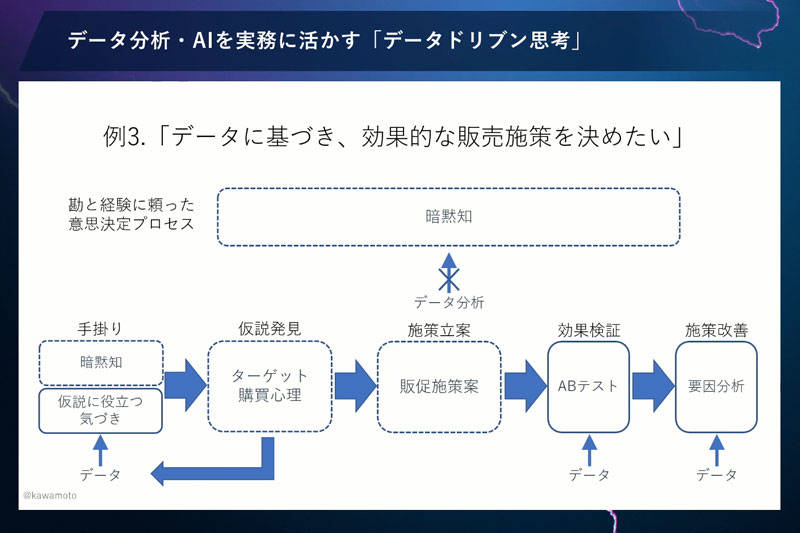
まとめ:データドリブンな意思決定プロセスとは
3つ目の事例でわかるように、じつはデータドリブンな意思決定プロセスは、非常に長いですね。かつ、さきほどの原因追及の場合もそうですが、決してデータ分析だけでプロセスできるわけではありません。現場担当者だからこそもっている、さまざまな仮説や原因に対しての暗黙知も必要であると強調しておきたいと思います。

6つに類型化される意思決定プロセス
私のこれまでの経験上、データドリブンな意思決定プロセスは、6つの種類に類型化することができます。
- 反復選択型
- 計画策定型
- 体制選択型
- 原因特定型(課題発見も含む)
- 仮説試行型
- 経営判断型
それぞれでデータや AI の役割が決まってきて、かつデータドリブンな意思決定プロセスも決まってきます。先ほどの事例1が反復選択型、事例2が原因特定型、事例3が仮説試行型に該当します(下図)。
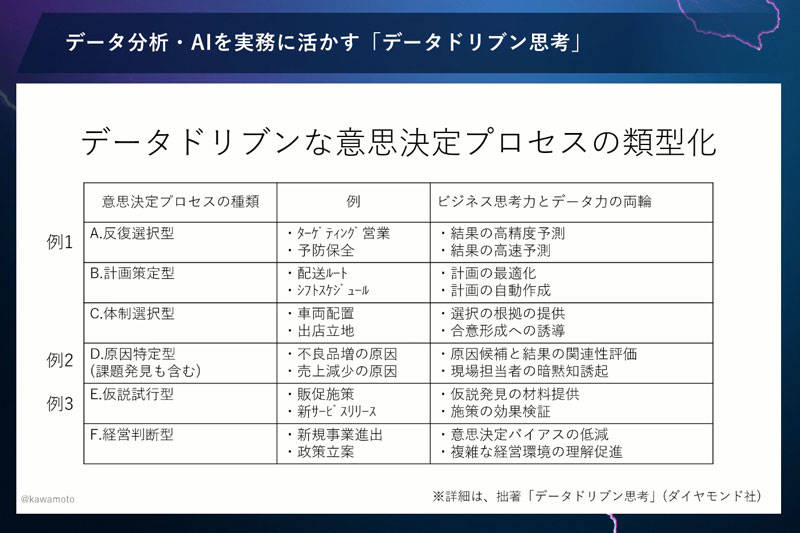
このように類型化しておくと、そのプロジェクトに合った意思決定プロセスがわかるので、比較的進めやすいと思います。
ここまでの話を整理します。まず「ビジネスの課題の設定」をする。その課題を解決するために、どのような「データドリブンな意思決定プロセスを設計」したらいいかを考えます。それを実現するために、「データと仮説や因果関係に関する知識の両輪でプロセスを実行」する。このような流れで進めていきます。
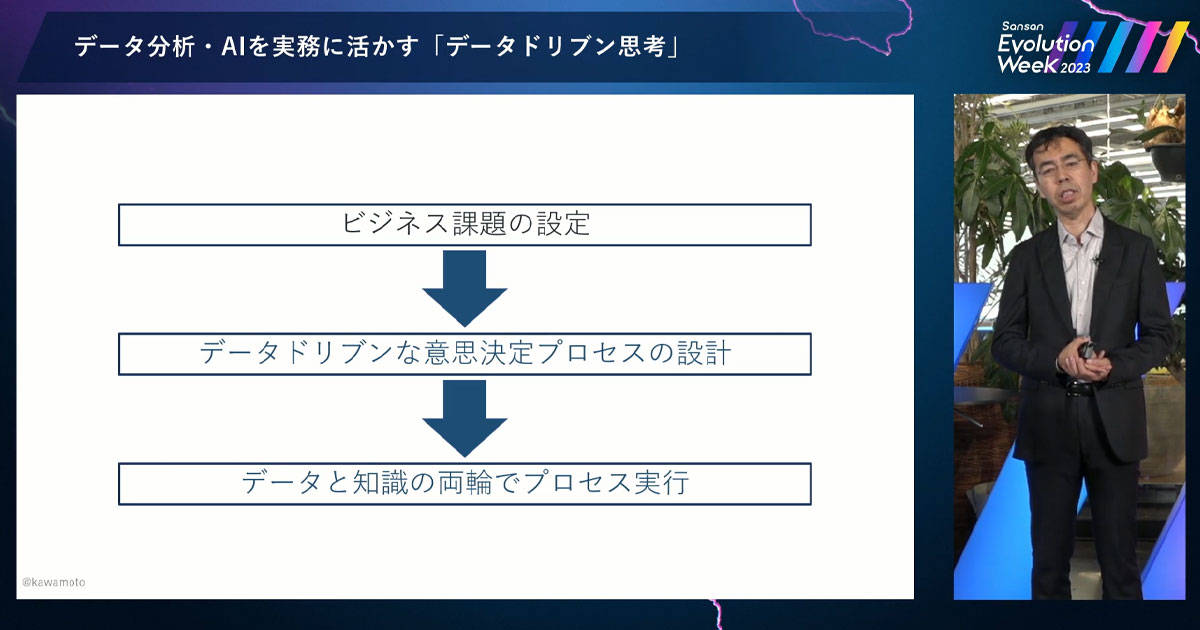
ビジネスの課題設定
ここまで、「データドリブンな意思決定プロセスの設計」と「データと知識の両輪でプロセス実行」について説明してきました。「ビジネスの課題の設定」は、データや AI を使わなくても必要な、ビジネスパーソンとして基本的な能力ですよね。
ただ、みなさんは、ビジネスの「課題」を設定できているでしょうか。私が企業向けにセミナーをするときに、まずお願いするのは、仕事の課題を書いてもらうことです。そうすると、問題を飛ばしていきなり課題設定したり、狭い視野で課題設定したり、データや AI の活用自体を目的化したような課題設定をしたりといったことが散見されるんですね。
ここでの「問題」や「課題」とは、以下の通りです。
- 問題:達成したい目標と現実の差
- 課題:その差を埋めるために成し遂げるべきこと
また、課題の掘り下げ方が不十分な場合もあります。たとえば、「在庫過不足にならないように発注する」「活躍できる人材を採用する」「購買率アップにつながる販促施策を打つ」。このようなざっくりとした課題認識では、解決するための糸口を考えることすらできないんです。
ここで思い出していただきたいのは、冒頭のカーネマンさんの言葉(「組織とは、意思決定を生産する工場である」)です。その意味するところは、すべての問題は意思決定プロセスのまずさに起因するということです。
ということは、すべての課題は、意思決定プロセスの課題――もう少し日本語的に表現するなら、「***の決め方を~に改善する」という表現に掘り下げられます。

これを意識すると、普段みなさんがざっくり考えている課題をより掘り下げられると思います。

いくつか意思決定プロセスの課題を挙げていますが、そのうちのどれになるかによって、意思決定プロセスを具体的にどのように変えていくのかが変わります。
ここまで掘り下げることができれば、つぎのステップのデータドリブンな意思決定プロセスを設計できるようになってくると思います。
ここまでをまとめると、まず、「ビジネスの課題を設定」する。これができていない人も多いです。さらに掘り下げが甘い。そのため、「意思決定プロセスの課題に掘り下げる」。そこまでくると、「データドリブンな意思決定プロセスを設計」する。データドリブンな意思決定プロセスを実行するためには、データだけでなく、仮説や因果についての暗黙知も活用し、両輪で「プロセス実行」していく。これが私が呼ぶ「データドリブン思考」です。
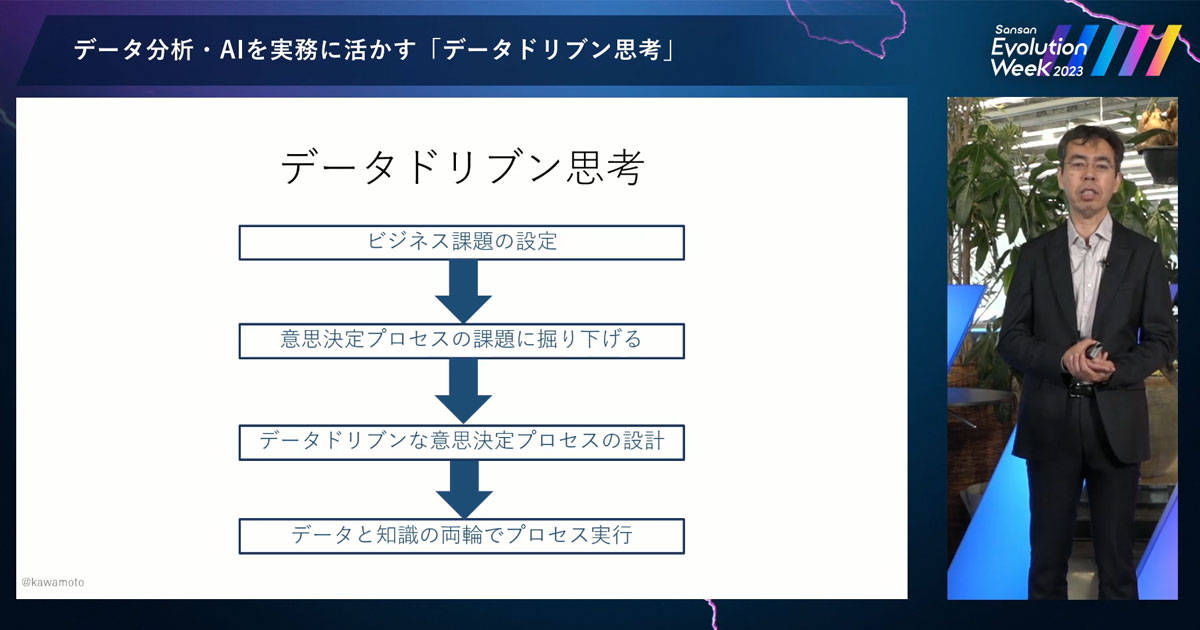
データドリブン経営の実現
現場の担当者から経営者まで、会社のすみずみまでデータドリブン思考が広がることが「データドリブン経営」だと思います。データドリブン経営を実現するには、誰が何をすればいいかについて説明します。
データドリブン思考は、意思決定のプロセスをよくするための思考です。当然、主役は当事者である意思決定者で、データサイエンティストは意思決定者によるデータドリブン思考の一部をサポートする役割に過ぎません。
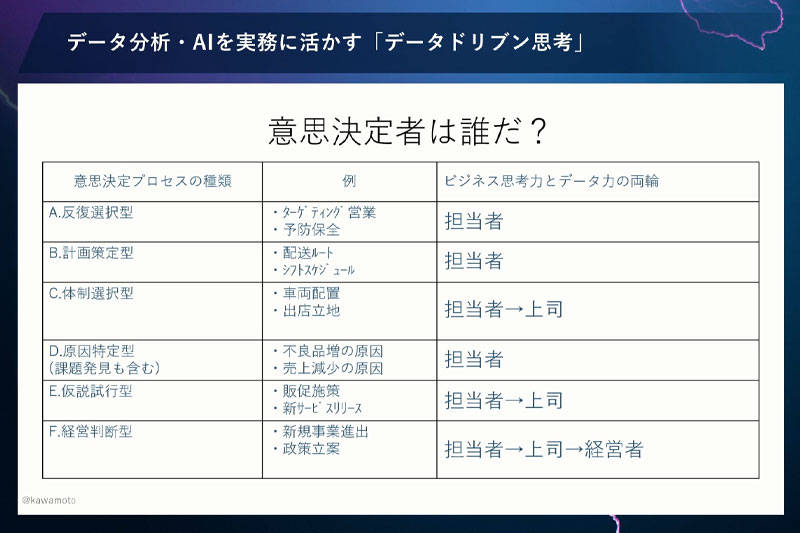
では、意思決定者は誰か。さきほどの意思決定プロセスの6つの類型にそって説明します。
反復選択型、計画策定型については、担当者自身が決めれば完結するので、意思決定者は担当者だけです。
一方で体制選択型は、担当者が決めても上司の了承が必要です。意思決定者は担当者と上司です。
原因特定型は、たとえば工場の不良品原因追及程度なら担当者で完結します。
仮説試行型は、新たな施策を考えて実行するとなると、上司の確認が必要です。担当者だけでなく上司も意思決定者となります。
経営判断型は、上司どころか経営者を巻き込んでの意思決定になります。
データドリブン思考のために必要な3つの能力
意思決定者にとって、データドリブン思考をするために求められる能力とは、以下の3つです。
- 課題発見力・・・課題を設定する
- プロセス設計力・・・課題を解決するための意思決定プロセスを設計する
- データ活用力・・・データと知識の両輪でプロセスを実行する
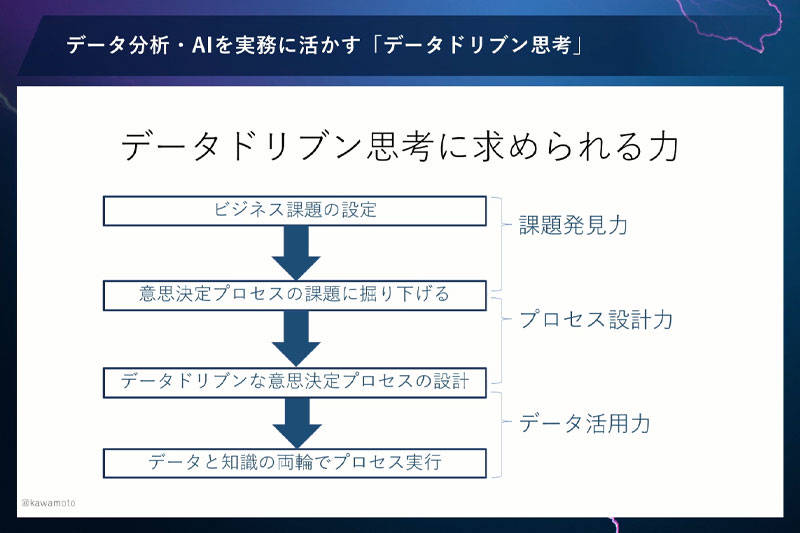
この3つのうち、もしすでに「課題発見力」と「プロセス設計力」が習得できているなら、あとは「データ活用力」さえ身につければいい。しかし、残念ながら日本のビジネスパーソンの多くは、課題発見力が非常に低いです。また、意思決定のプロセス設計力は、もしかしたらそれをしようという意識すらないかもしれません。
データ活用力だけでなく、この3つすべての能力を身につけないと意味がないのです。にもかかわらず、データサイエンティストの育成や、データ基盤の構築などといった、データ活用力を深めることばかりに注力しがちです。
たとえるなら、料理の作り方も知らないのに、調理器具の使い方ばかり深めているのと同じです。その結果、「わかる」止まりで「役立つ」に至らない状況に陥っているのではないかと思うんですね。
では、この3つの能力はどうすれば身につくのでしょうか。
課題発見力の育て方
課題発見力とプロセス設計力は、データや AI を活用しない場合でも必要な力です。ビジネスで成果をあげるためには必修の力ですよね。にもかかわらず、なぜ日本のビジネスパーソンは課題発見力・プロセス設計力がつたないのか、どうすればそれが鍛えられるのかについて、持論を述べたいと思います。
多くのビジネスパーソンの課題発見力が育たないのは、能力がないからではなく「課題発見する動機がないから」ではないかと思っています。
みなさんは、普段のお仕事のなかで、課題をはっきりさせたいという動機をもってお仕事をされていますか? 課題を発見して上司に報告したら、「課題だけもってくるな」「解決策も合わせてもってこい」といわれたことはないでしょうか。
私は、日本企業において、課題を見つけるという価値観が非常に低いと思うのです。当然、課題を発見する力を培えるはずがありません。
私は、課題発見を成果としてもっと評価するようにすればよいと考えています。課題を発見したことを、その人の人事評価などにも反映する。そうすれば、社員は課題発見に時間をかけるし、課題発見力を養おうと考えます。また、みんなで力を合わせて課題を発見する動機になるのではないかと思います。
プロセス設計力の育て方
プロセス設計ができない理由は、能力がないからではなく、プロセス設計をしようという意識がないからだと考えています。
日本では、なんとなくみんなが「これでいいか」という雰囲気になると、「それでいいんですか」と問いにくい空気感がありますよね。これが大きな問題です。「なぜそのように決めたのか」を徹底的に問う風土を作る必要があります。
具体的には、「なぜ」と問いにくくする空気感を解消する、立場に関係なく「なぜ」と問えるようにする、前例や現状を否定する「なぜ」を問えるようにするということです。
データ活用力とは
データ活用力は、課題発見力やプロセス設計力と違い、データと AI を使うからこそ、新たに必要となる能力です。意思決定者に求められるデータ活用力とは何でしょうか。
おそらく、多くのビジネスパーソンが、身につけるべきデータ活用力とはどのような能力なのか、わかっていないと思います。
実際に、企業向けのアドバイザーをしていると、こんな質問が飛んできます。
- 具体的にどんなデータ力(分析手法)を身につければいいのか?
- 分析手法さえ学べばデータ活用できるのか?
- 上司や経営者にはどのような能力が必要か?
この質問に答える形で、どのようなデータ活用力が意思決定者に必要なのか、述べていきます。
どんなデータ力(分析手法)を身につければいいのか?
少なくとも、ビジネスパーソンが身につけるべきデータスキルは、エンジニア力、データ分析力、データ読解力の3つに分類して考えるべきだと私は思っています。
- エンジニア力・・・機械学習などのモデルを開発して実装する、そしてデータの計測、収集の仕組みを作るといった実装能力
- データ分析力・・・数学やプログラムが必要なものではなく、基本的な分析(分解、比較、変化、関係性、分類)ができる力
- データ読解力・・・基本的な分析の結果を正しく解釈する力、恣意的な分析を見抜く力
分析手法さえ学べばデータ活用できるのか?
さきほどの6つの分類にそって説明するとこの表のようになります。
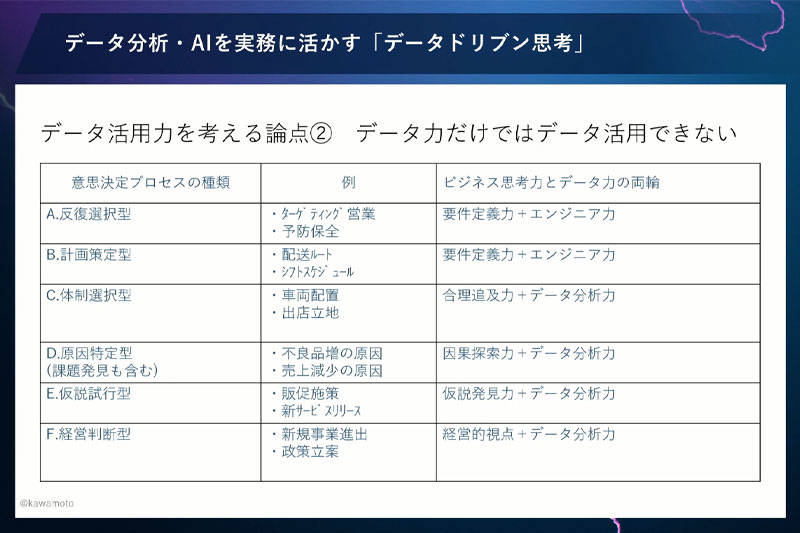
反復選択型・計画策定型の場合、要件定義力とエンジニア力が必要です。顧客ターゲティングや予防保全活動では、誰が買ってくれそうか、どの部品が故障しそうかなどを、機械学習で予測するモデルを作るんですね。そういう意味では機械学習モデルを作るエンジニア力が必要です。ただ、その前に、どういった要件を満たす機械学習モデルを作ったらいいかという要件定義をする力も必要です。
体制選択型では、合理追求力とデータ分析力が必要です。どういった判断基準でどんな判断材料で意思決定するか、その合理的なロジックを考えなければなりません。
原因特定型においては、データ分析でわかるのはたかだか関連性までです。なので、それだけでなく、因果関係を探索する力と、データ分析力との両輪で考える必要があります。
仮説試行型は、仮説を考える力と、仮説を検証するためのデータ分析力、さらにデータ分析をした結果から仮説を考えるといったように、仮説発見力とデータ分析力の2つが必要です。
経営判断型については、データ分析力だけでなく、「経営的な視点でデータを見る」「データから経営的な洞察を得る」といった2つの能力がないとはじまりません。
つまり、データスキルだけでは、データ活用はできないということです。
上司や経営者にはどのような能力が必要か?
この問いについても6つの類型にそって説明します。
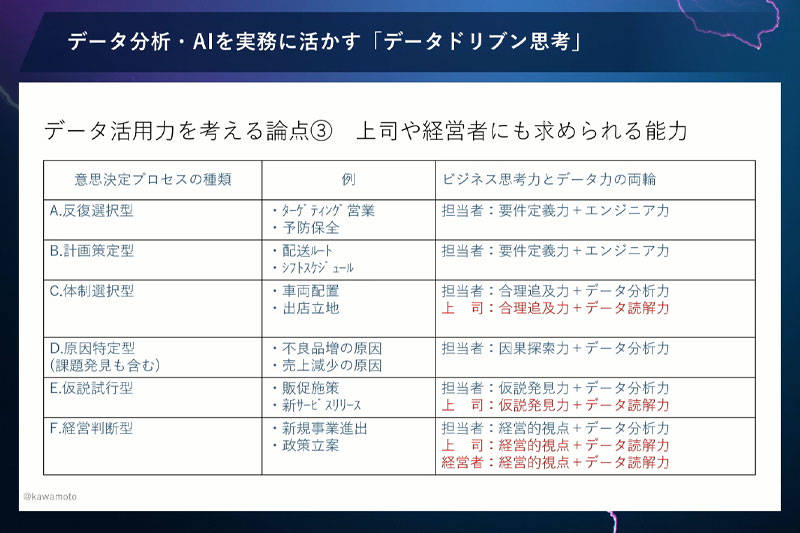
反復選択型や計画策定型、原因特定型は、担当者で自己完結しますので、上司は登場しません。
一方、体制選択型の場合は、最後に上司が決めますから、上司には合理追求力と、データ読解力が必要だと思います。上司が持つべきデータ分析力というのは、すなわち、部下が持ってきたデータをきちんと正しく理解できる能力です。
仮説試行型では、上司も仮説発見力とデータ読解力が必要になってくると思います。
経営判断型となると、経営者も登場しますから、経営的視点とデータ読解力、この2つが必要になってきます。
部下が持ってきたデータを理解するという観点だけなら、上司や経営者はデータを正しく読解する力さえあればいいということになります。ただ、私はそれだけでは足りないと思います。上司・経営者自身が、データを自分で見ていく力、データ分析力が必要です。
能力だけでなくモラルも問われる
データ活用力を考えるにあたって、もう1つ論点を挙げます。能力だけではなく、モラルも問われるということです。ここでいうモラルのない分析とは、恣意的な分析や不都合な分析結果の隠ぺいなど、無責任な分析をすることです。
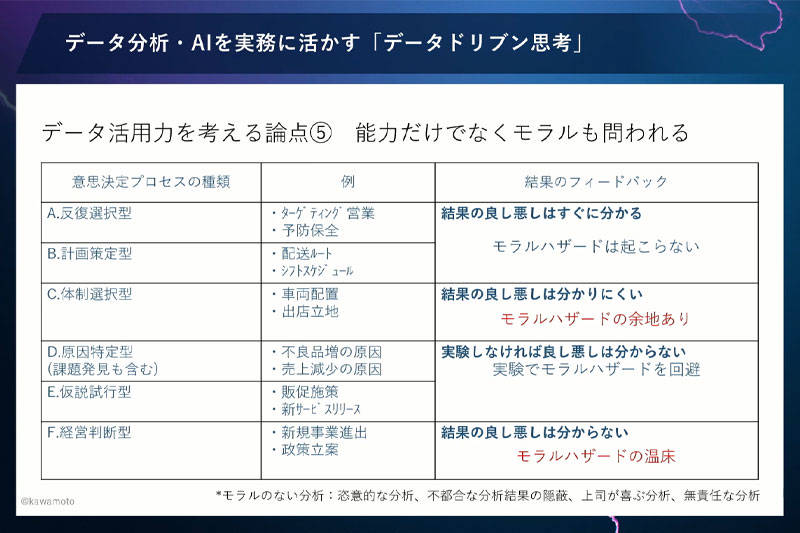
反復選択型や計画策定型は、結果がはっきりわかります。機械学習モデルや最適化モデルと、データドリブンなプロセスを作った結果、その良し悪しがわかりやすいので、モラルハザードが起こりにくいです。
一方で、体制選択型は、もし違う決定をしていたらどうなっていたか、結果がわかりにくいです。そのため、モラルハザードの余地がでてきます。
原因特定型や仮説試行型は、実験すれば結果がわかります。実験しなければ良し悪しはわかりません。大切なのは、きちんと実験してモラルハザードを回避することです。
経営判断型が一番問題です。経営判断の結果は10年後、20年後にわかります。そのとき、経営判断した経営者も担当者ももういなくなっているかもしれません。そういう意味では、モラルハザードの温床になり得ます。
データ活用力の育て方
データ分析&仮説発見の場合
データ分析と仮説力を育てるコツは、仮説・分析・解釈の各ステップをしっかりと言語化することです。
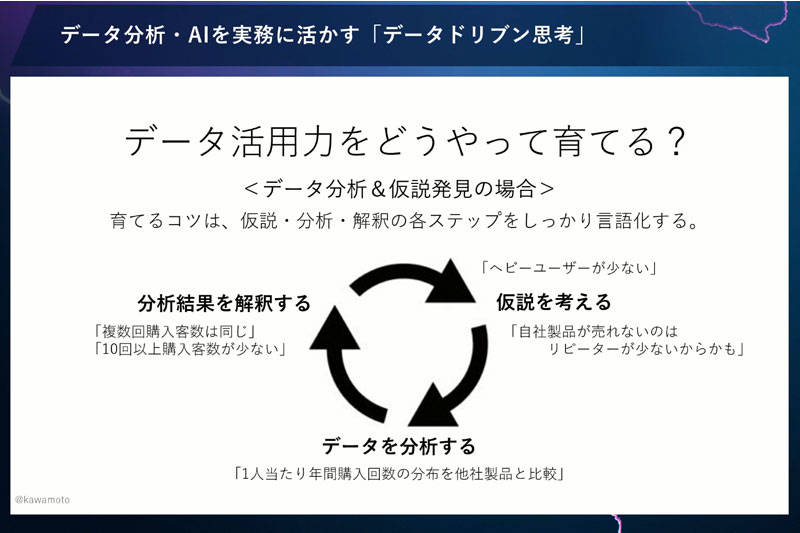
たとえば「自社製品が売れないのはリピーターが少ないからだ」という仮説を考えたとします。それを検証するためのデータ分析はどうすればいいでしょうか。1人あたりの年間購入回数の分布を他社製品と比較し、そこから得られた結果の解釈をきちんと言語化してみます。その結果、複数回購入した人数は同じぐらい、10回ぐらい購入する人数は非常に少なかった。その解釈から、新たに「ヘビーユーザーが少ない」という仮説が生まれます。
このように、仮説・データ分析・結果の解釈をしっかりと言語化していくことが重要です。
データ分析&因果探索の場合
データ分析と因果探索力をどうやって育てるか。これは、因果関係を構造的に可視化していくのがコツです。

具体的には、まず因果関係を構造的に、グラフを使いながら探索していく。つぎに、因果関係の結果を目的変数、原因を説明変数とした解析をする。それから、関連性の大きいものは影響も大きいだろうと評価し、因果関係にフィードバックする。そして因果関係の探索をあらためておこなっていく。これを繰り返すことで、データ分析力と因果探索力が育てられていくと思います。
2つの例を挙げました。このように、データ活用力の習得とは、数学プログラミング力の育成と違い、データを自分の思考に組み込むため型を会得することです。
一気通貫で3つの能力を身につけることが重要
データドリブン思考に求められる「課題発見力」「プロセス設計力」「データ活用力」について紹介しましたが、3つも習得するのは大変だと思う方もいるかもしれません。
申し上げたいのは、課題発見力とプロセス設計力がないのに、データ活用力だけがんばっても意味がないということです。ほどほどでいいので、一気通貫で3つの能力を身につけることが大切です。
みなさんには、そのヒントとして、大学で学生たちに教えるときに使っている3つの問いについてお伝えします。
課題発見力をつけるための問いは、「課題は何ですか?」
プロセス設計力の問いは、「なぜそう決めたのですか?」
データ活用力の問いは、「何を見るためにデータ分析するのですか?」です。
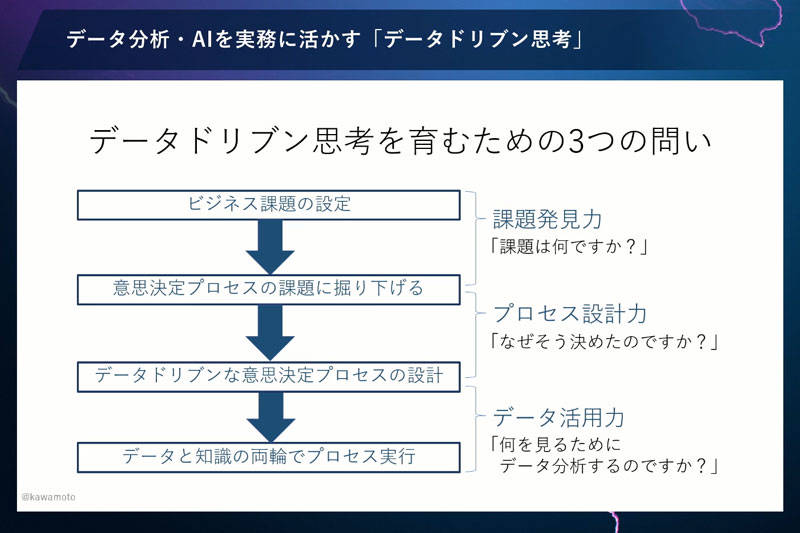
この3つを普段から言語化すると、ほどほどのデータドリブン思考を一気通貫で身につけられると思います。
データドリブン経営を目指して
多くの企業の方とお話をしていると、データドリブン思考を身につけることができても、実際にそれを実行することができないとおっしゃいます。
なぜそうなるかというと、日本の企業は、統制型の組織だからだと私は思います。そうではなく、自律的な組織にならなければいけません。

データや AI が台頭していくなかで、仕事の仕方も変化しなければならない。統制型の組織のままでは、日本の企業は生き残っていけないですよね。
データドリブン経営を目指してやるべきことについてまとめます。
- ビジネス担当者・・・データドリブン思考を自分ごとと捉え、習得し実践する。
- DXの推進部署・・・ビジネス担当者のデータドリブン思考を併走し育てる。プログラム力や数学力なしでもできる環境づくりをする。
- 経営者・上司・・・企業を統制型組織から自律型組織に変革する。
データドリブン経営は、ゆっくりで、見えない変革だと私は思います。
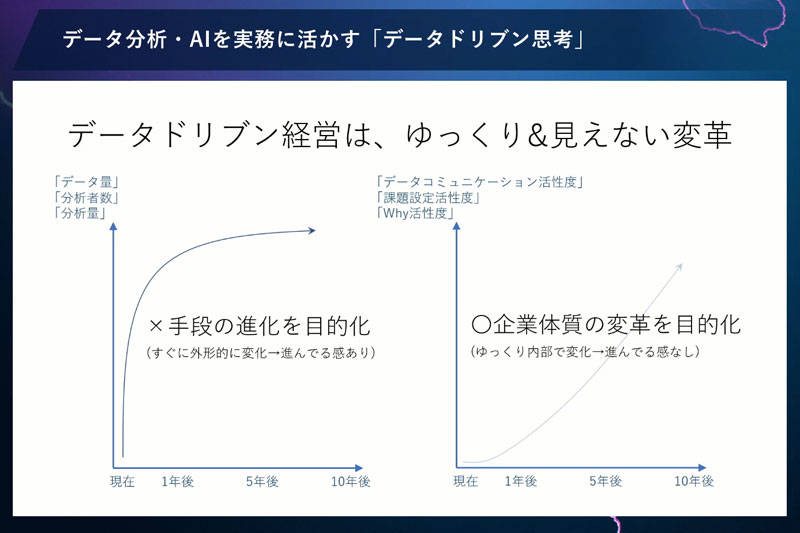
データドリブンな経営のバロメータとして、データ量や分析者数とよくいいますが、これは手段を目的化していますよね。そうすると、見えやすいしすぐに達成できますから、そういう意味では楽です。
しかし、データドリブン経営は企業体質の変革ですから、バロメータは「なぜ」の活性度や課題設定の活性度といった目に見えない、かつゆっくりしたものになります。そういったなかで忍耐強く取り組もうと思うと、経営者の役割が重要です。経営者が社員と対話し、その重要性を語り、社員のデータドリブンへの温度感を把握しながら、育てていくことが大切なのです。

 New
New








