
サービス設計やビジネスにおいて、データを徹底的に活用して意思決定をおこなっている Google。同社を世界のトップ企業へと成長させた、検索エンジンやメールなどの進化の背景や歴史、そして AI やデータの活用を通じて変革をもたらしたストーリーとは? Alphabet Inc. 現会長の ジョン・ヘネシー氏が語りました。
Sansan株式会社が2023年6月に開催した「Sansan Evolution Week 2023」の講演内容をもとにお届けします。
Google の出発点となった重要な気づき

ワールドワイドウェブ(www)の黎明期、Google社の誕生前は、別の企業が検索機能を提供していました。このような企業はたくさんの Webページを調べます。そして、Webページを探すためにリンクを使ってクローリングしていました。当時の検索では、検索のキーワードが頻繁に使われている Webページが表示され、リンク情報は、検索結果に反映されていませんでした。
Google のラリー・ペイジとセルゲイ・ブリンは、スタンフォード大学の院生だったころ、重要なことに気づきました。彼らは、リンクの重要性を明らかにしたのです。この重要な気づきが、Google社の出発点となりました。
非常に有名な25年前の論文があります。Google社の誕生につながるアルゴリズムの特許、ページランクについて書かれたものです。ここで主張されているのは、重要な Webページのなかで言及されている Webページもまた、同様に重要であるということです。これこそが鍵となります。
当時、業界には多数の検索プロバイダーが存在しましたが、Google の検索アルゴリズムは当初からそれらを超越していました。
データドリブンなビジネスを構築する際の課題の1つは、結果を操作させないようにすることです。結果操作の例はあとを絶ちません。人々はつねに Google検索の結果を操作し、順位を上げようとします。そのため、アルゴリズムによりこれを防ぐ必要があります。さもないと検索結果は役に立たないものになるからです。
まず、コアアルゴリズムでこれに対処すべきです。しかし、同時にアルゴリズムの継続的修正も必要です。そうしなければアルゴリズムの有効性は失われてしまいます。これこそ Google の重要な機能です。データドリブンの優れたアルゴリズムがあっても、絶えず改善していく必要があるのです。
検索結果の進化

検索は時間とともに進化してきました。最適な検索結果を提示するにはどうすればよいのか。また、検索結果が適切かどうか、どうすればわかるのでしょうか。
私たちは、Web がまだ小規模だったころ、ユーザーを集めて検索結果を評価してもらっていました。しかし、Web が急激に拡大したことで、検索結果の品質を判断する別の方法が必要となりました。
そこで、重み付け評価をおこなうようになったのです。たとえば、何人かが同じ検索をするとします。全員が1つ目のエントリーではなく、3つ目のエントリーをクリックするのなら、アルゴリズムを調整すべきです。3つ目のエントリーの優先度を上げ、最初に表示されるようにしなければなりません。
これが検索に起きた次なる進化でした。こうした進化において、ユーザーは、検索をする際に品質が高いとされる情報や出版物の内容を照らし合わせるようになります。これらに重み付けをおこなうことで、回答の合理性を改善したのです。
約8~9年前、私たちは Google検索を抜本的に改革し、コアテクノロジーとして機械学習を使い始めました。機械学習によって、より多くの要素を検索プロセスに組み込むことが可能になります。
たとえば、検索履歴の表示や、スペル修正などです。スペル修正は検索においてもっとも重要な機能の1つです。タイプミスはつねに起こるものですから。
さまざまな人が多種多様な内容を検索します。ですから、機械学習システムを使い検索結果を最適化するわけです。こうして Google検索では、長期間かけて構築された機械学習システムが活用されています。
ビッグデータ活用による迷惑メールフィルタの進化
ビッグデータ活用の事例をご紹介します。Gmail では、非常に早い段階から迷惑メールフィルタを計画していました。すでに15年前の時点で、迷惑メールの増大が問題視されていたからです。
そこで、どのメールが迷惑メールかを正確に検出できる仕組みを構築する必要性が生じます。このために、私たちはサポートベクターマシンという技術を活用していますが、詳細は割愛します。いわゆる大量のメールを取り込んでシステムを訓練するというものです。最初のうちは人手を介して訓練していきます。迷惑メールかどうかを1つずつ判定させていって、セパレーターを構築していきます。これは迷惑メール、これは普通のメールと分類します。

当初はメッセージ本文から判定することができました。やがて、複雑な機械学習を活用してメッセージ本文の確認をするようになります。メーリングリスト宛か個人宛か、以前にやりとりがある相手か、件名があるか、返信用のアドレスは正確か。このようなポイントを確認します。これらによりフィッシング詐欺が抑止できるのです。
数百万のユーザーがいるシステムなら、迷惑メールの判定は非常に頻繁におこなわれます。仮に、何百万人いるユーザーのうち、1,000人が「これは迷惑メールだ」と判定した場合、その信頼性は高いと考えることができます。これにより、迷惑メールフィルタの品質は劇的に改善しました。迷惑メールやプロモーション、ソーシャルメディアのメッセージ、フィッシング詐欺や危険性の高いメールなどを分類できるようになります。完全な分類の実現もまもなくでしょう。進化をしてきたからこそのテクノロジーといえます。
変化に合わせて最新の流行をつねにフィルタリングする
データ主導型に起因する興味深い問題をご紹介しましょう。レコメンデーションシステムの構築に関する問題です。
わかりやすい例として、Netflix などストリーミングサービスでつぎに観る映画やテレビ番組を勧めてくれる、レコメンデーションシステムなどがあります。このシステムについて、「一般的なやり取りを通じ、方向性を提案するもの」としてとらえなおしてみましょう。
顧客からのリクエストを受ける、インターフェイスのシステムについて考えてみます。顧客が電話をすると「〜でない場合は1を押してください」といった自動案内が何度も繰り返されることがありますよね。これはあまりよいとはいえません。30分も自動案内で堂々巡りしてしまうと、やはり人と話したほうがよいと考えます。
そこで、レコメンデーションシステムを使い、ユーザーとやり取りをおこないます。Amazon などもレコメンデーションシステムを導入し、動画や商品の分類をおこなっています。過去の購入履歴や類似したユーザーの行動をもとに、おすすめを提案します。同じ商品を購入した別のユーザーを探し、そのユーザーが購入する別の商品を確認、あなたのおすすめ内容に反映するという仕組みです。こうしたレコメンデーションシステムは、対ユーザーコミュニケーション全般において、多くの用途をもたらします。そして、その重要性は増す一方です。
しかし、レコメンデーションシステムには演算に関わる困難な問題があります。世界中に何本の映画があるでしょうか。Netflix で配信される映画は、全部で何十万本。私は1,000本ほど見てきましたが、それをもとに膨大な量の映画を演算することなど不可能です。そこで、このようなレコメンデーションシステムの管理をどのようにおこなうかが問題となります。
限られた数の映画をもとに、つぎに観るべき映画を推論するには、どうすればよいでしょうか。効率よく答えを導き出すには、特別な演算能力が必要です。この演算モデルを迅速に更新していくことも課題です。

たとえば、サッカーワールドカップが開催間近であるとします。「アルゼンチン対スペイン」とユーザーが入力するとき、何が求められるでしょうか。両国が何かで対立している情報を知りたいわけではなく、ワールドカップの試合の日時を知りたいのではないでしょうか。オリンピックも同様です。オリンピックについて質問される可能性がある内容を、システムに取り込んでいく必要があります。
こうしたレコメンデーションシステムでは、つねに変化するデータを活用できるようプログラミングされています。世界的なイベントがある場合や、Netflix で配信される新番組が反響を呼びそうな場合に変化が生じるかもしれません。
理解しておくべき大切なポイントは、データ主導型のシステムはこうした要素に対し、動的で応答性に優れているべきだということです。これらを把握し、優れたレコメンド機能を実現するには、つねに最新のデータが必要です。ものごとの変化に合わせて最新の流行をつねにフィルタリングする必要があります。こうした分野はいままさに始まったばかりです。
つねに測定し、品質を高めること
データ主導型の思考法を企業内でいかに管理し浸透させていくのか、あらゆる場面でこの意識を持つにはどうすべきかお話しします。
例の1つとして、A/Bテストを挙げましょう。これは非常にシンプルなテストです。異なる選択肢を異なる対象者に提示して、どのような結果となるかを確認します。選択肢は A か B のパターンだけでなく、3パターン以上の場合もあります。はっきりと予測できないことも多いため、実際に試してみるというわけです。どのパターンがよいかをあらかじめ把握する方法など存在しないからです。潜在顧客である対象者をグループ分けして、A~D のパターンをそれぞれ提示します。そのなかで評価が高かったものを採用するという方法です。
実際の活用例をご紹介しましょう。どのくらいの広告数を表示するべきか、実験をおこないました。

広告や検索結果にどのような色を用いるべきか、色を変更することで違いが発生するのか、フォントによって違いがあるのか、などです。そんなささいなことで大きな影響が生じるはずはないと、みなさんは考えるかもしれません。しかし、大規模なビジネスの場合、0.1%が大きな違いを生み出します。
検索結果の分割や、新しいユーザーインターフェイス、Gmail のデザインなどについて、2つのパターンをユーザーに試してもらい、どちらを好むか確認します。
Gmail であれば、メッセージ間をどれくらい迅速に切り替えられるか、返信や転送などにどれくらいの時間がかかるかなども測定できます。そしてユーザーの操作の実態をもとに、これらを最適化することができるのです。
では、なぜ測定が必要なのでしょうか。それは、インターネットの世界では、ユーザーの満足度が非常に重要だからです。応答性やユーザーの満足度を高めることが、真の差異化要因となります。ユーザーの関心は、正しい答えをできるだけ早く入手できるかどうかにあります。つねに測定し、品質を高めることが企業にとっては非常に重要なのです。
AI が劇的な進化を遂げている理由
AI のディープラーニングの革命について全体像をお話しします。これは IT の歴史上、もっとも重要な出来事であり、トランジスタの発明やデジタルコンピューターによる変革以来となるものです。この2つから世界の産業全体が生まれたのですが、ディープラーニングはそれに匹敵する技術です。
この技術の応用範囲は飛躍的な広がりを見せています。AlphaGo(※1) が囲碁チャンピオンに勝利するというブレイクスルーが早期段階で起こりました。AI業界の人間ですら、あの勝利に到達するには 10~20年はかかると考えていました。それほど技術は劇的に進化しているのです。
(※1)Google DeepMind によって開発されたコンピュータ囲碁プログラム
そして、ImageNet(※2)と画像認識です。画像認識こそが自動運転車を推進する技術です。自動運転車には必ず優れた画像認識技術が搭載されています。自転車と歩行者と車を識別し、それが動いているかどうか識別できなければなりません。また、一時停止の標識や信号を認識する機能が必要です。このような複雑な問題に対処するアルゴリズムは、機械学習の技術がなければ作成できません。
(※2)物体認識ソフトウェアの研究のために設計された大規模な画像データベース
そして、私のお気に入りの事例があります。Google とスタンフォード大学の医学部が共同構築した、皮膚の病変を見てがんであるかどうかを判断するシステムです。このシステムは、いまや医師団と同等のパフォーマンスを発揮することができます。大量のデータで訓練した結果です。
事実、皮膚科医などを養成する際に用いるのとまったく同じデータで訓練しています。このため、非常に高い性能を持つのです。
自動翻訳も、ラテン語をベースとする言語ではバイリンガルと同等の翻訳ができるまでになりました。英語と日本語ではそこまでに至っていませんが、1~2年もすれば達成できるでしょう。
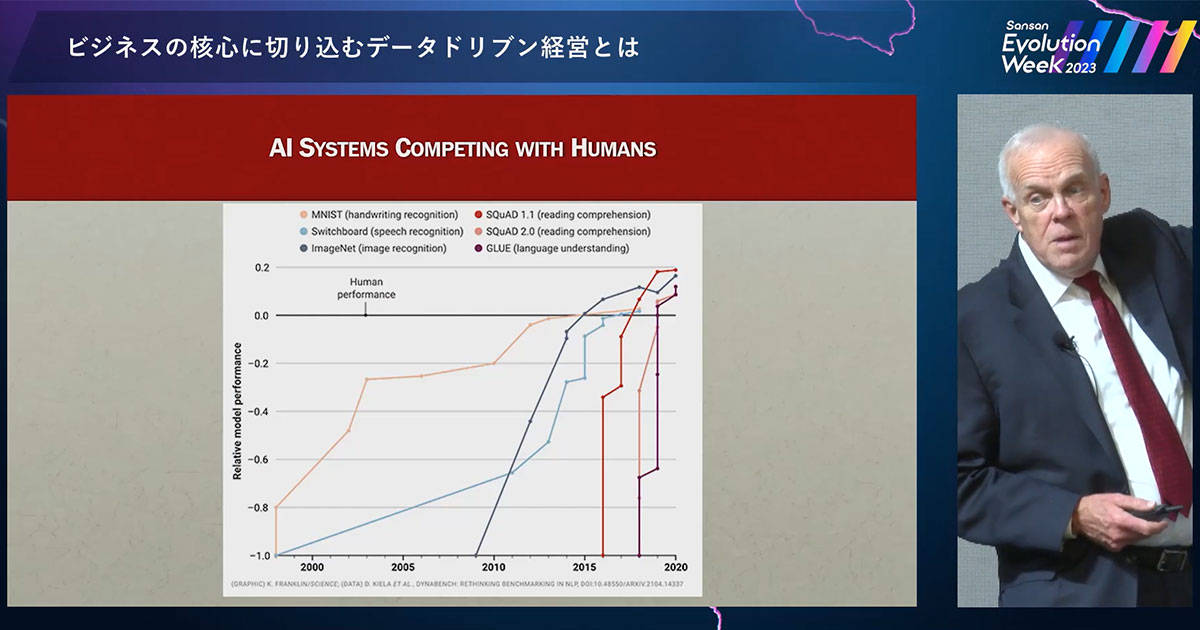
これは最近見つけた興味深いスライドです(上図)。黒い線は人間の性能を示し、すなわち人間の優位性を示しています。ここに示すさまざまなタスクについて、人間に比べ、AI がいかに優れているかがわかります。画像認識や手書き文字認識、音声認識などはすべて改善されています。
過去2年間に注目すると、グラフの線はほぼ垂直になっています。ChatGPT などのいわゆる大規模言語モデルがここで登場したのです。これらの分野はここ数年で利用が始まった技術です。
大きなブレイクスルーを経て、いまもこの分野は進化を続けています。私はコンピューターサイエンスに45年携わっていますが、このように進化する領域を見たことがありません。驚異的なスピードです。
この進化の理由とは、すべての技術を成功に導くブレイクスルーが突如起きた理由とは何なのか――。いくつかポイントがあります。
まず1つ目は、アルゴリズムのブレイクスルーです。ディープラーニング、誤差逆伝播法、埋め込み、機械学習の一種である強化学習、大量のデータや科学者・専門家の存在です。
そして2つ目は、大規模言語モデルや基盤モデルと呼ばれるもの―― ChatGPT はその基盤モデルです。これらは非常に大規模で、自然言語を一般的な知識と組み合わせています。2つの要素が結合しているのです。単なる自然言語や一般知識ではなく、2つの組み合わせであるがゆえに強みを発揮するのです。
3つ目は、システムを訓練するための膨大なデータです。訓練用のデータがなければ、システムの知能は低いままです。一般常識も持ち合わせていません。データセットから学んだことしかわからない状態です。www やウィキペディア、ImageNet など、訓練用に膨大なデータが必要になります。これは非常に重要です。
そして、データが良質でクリーンである必要もあります。ウィキペディアの99%は正確な情報ですから、十分に良質だといえるでしょう。システムの質は訓練データ次第です。また、数千億もの変数を使用するため、大量の演算リソースも必要です。世界でもっとも大規模な演算が必要となるのは、このような AI の訓練なのです。つまり、計算上、訓練のコストはきわめて高くなります。
さきほども少し触れた、ImageNet について紹介します。ImageNet は、インターネット上の画像に写っている物体を、「馬」や「犬」などのラベルを付けることで分類し、膨大なデータセットを作り上げるために構築されました。
画像認識システムの訓練には、ImageNet のようなデータセットが使われます。人間を超越する可能性を持つ理由とは、このシステムが違いを見分けられるからです。犬か猫かを区別するだけではなく、犬の種類まで判断できます。人間にとってはかなり難しいことですが、システムではこのレベルまで訓練できるのです。
ただ、システムは人間と同じように考えるわけではありません。たとえば、私の4歳の孫娘に「なぜあれが猫なのか」と尋ねてみます。「耳がとがっていて犬よりふわふわしていてしっぽが丸まっているから」。彼女ならそう答えるでしょう。しかし、システムはそのように考えてはいません。システムは犬と猫の画像を大量に見ることで、初めて見る画像に対して判定をおこないます。統計的に犬と猫のどちらに近いかを判断するのです。このような統計的判断は、人間の思考とはまったく別のものです。
しかし、このようなシステムが世界を変えつつあります。その理由の1つは、いわゆる創発的行動に対応するようになったことです。システムの能力は私たちの想定を上回っています。私たちが考えるよりも知的で「思慮深い」振る舞いをします。これは大量のデータで訓練されているためです。
ChatGPT は Wikipedia の20~25倍のデータで訓練されていると考えられます。Wikipedia の情報量は、実際に印刷された世界最大の百科事典の約20倍です。つまり ChatGPT は、百科事典の500倍に相当する膨大な量のデータで訓練されているといえます。
また、非常に多くの研究がおこなわれ、日々新たな手法が生み出されています。数年前まで、翻訳には長・短期記憶と呼ばれる技術を使っていました。しかし、4年ほどでまったく使われなくなり、Transformerモデルという新しいシステムに置き換えられました。
ChatGPT も Transformer をベースとしています。入力文字列を出力文字列に変換し、重み付けを設定することで意味のある内容にします。ただし、信ぴょう性は判断されず、有害な回答も防ぐことができません。粗悪な訓練データを用いれば、粗悪な回答しか得られず、信ぴょう性はまったく問われないのです。
わかりやすい例を挙げましょう。ChatGPT にトピックを与えて作文させたところ、引用とともに文章が返ってきました。しかし、存在しない参照先の記事を挙げてきたのです。ChatGPT は、引用の形式は知っていても、そのトピックに関連した論文を引用しなければならないことは知りませんでした。
そこで、ChatGPT の開発者たちは、多くの人に ChatGPT を実行させました。回答が誤りである場合は、指摘してもらう。そしてその情報を取り込む。このようにシステムを微調整していくことで、つぎに同じ質問をされたときに正しい回答ができるようにします。訓練を最初からやり直す必要はありません。
ChatGPT には多くの魅力的な用途があり、フィードバックのために大量の人員を雇うという投資をするだけの価値があるのです。
AI は人間に匹敵するか

本日の締めくくりに、多くの人から問われる、じつに興味深い問いを投げかけたいと思います。AI が多様なタスクにおいて人間に匹敵する力を持つのはいつごろでしょうか。
特化型AI の対義語として、「汎用人工知能」と呼ばれるものがあります。1つの機能のみではなく、大変多くのことができる AI です。このようなシステムの実現は、日に日に近づいています。大規模言語モデルは少なくともこの10年間で大きく進化してきました。汎用人工知能もやがて実現するでしょう。
完全に人間に置き換わるわけではありません。人間の子どもは、物ごとをどのように学んでいるでしょうか。大人が横に座って、一字一句、言葉や絵を教えるわけではありません。猫だ、犬だ、魚だとすべてを教えたりはしませんよね。子どもは自然に知識を身につけるのです。システムにはそれができません。しかし、システムは非常に迅速に学習ができます。人間がチェスや囲碁で世界クラスになるには、20年以上かかるかもしれません。しかし、システムならたった24時間です。
しかし人間の脳には、コンピューターには決して超えられない、素晴らしい強みが1つあります。私たちの脳は、20ワット程度のエネルギーしか消費しません。一方、システムは訓練のために、その1,000倍ものエネルギーが必要です。1,000倍も必要なのです! 私たちには、神や進化により与えられた効率性や創造性がある。それに匹敵するものなど存在しないのです。
だからこそ、この分野では非常に刺激的で驚異的なブレイクスルーが生まれるはずです。人間は、付加価値を提供し真に創造性を発揮できるチャンスに溢れています。

 New
New
 New
New
 New
New
 New
New





